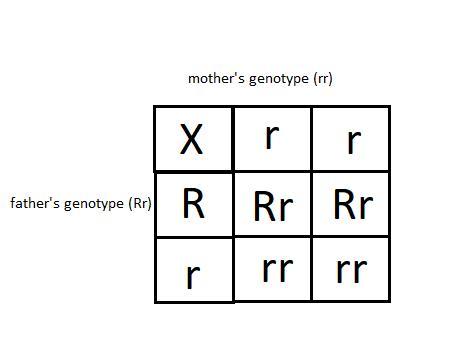
1. a) father (Rr), mother (rr)
b) from the attached file(1)
c) the possible genotypes are
d) but from the information given above the only possible genotype for SpongeGerdy is Rr, because we were told that she was squarepants
e) Rr
f) from the attached file(2)
g) the possible genotypes are
h) the genotypes for squarepants are RR and Rr
therefore probability is (25 + 50)% = 75% or 3/4
i) the only genotype for roundpants is rr
therefore probability is 25% or 1/4
2. a) wilba - Ee , wilbur -EE
b) from the attached file(3)
c) the possible genotypes are
d) the genotypes for round eye are EE and Ee
therefore probability is (50 + 50)% = 100% or 1
e) the only genotype for oval eye is ee
therefore probability is 0
3. a) squidward - BB . squidette - bb
b) from the attached file(4)
c) the only possible gene is Bb - 100% or 1
d) the genotypes for a light blue skin are BB and Bb
therefore probability is (0 + 100)% = 100% or 1
e) the only genotype for a light green skin is bb
therefore probability is 0
f) No, they are not. this is because they are heterozygous i.e.( they carry gene for a light green skin)
g) from the attached file(5)
h) the possible genotypes are
i) the genotypes for a light blue skin are BB and Bb
therefore probability is (25 + 50)% = 75% or 3/4
j) the only genotype for a light green skin is bb
therefore probability is 25% or 1/4