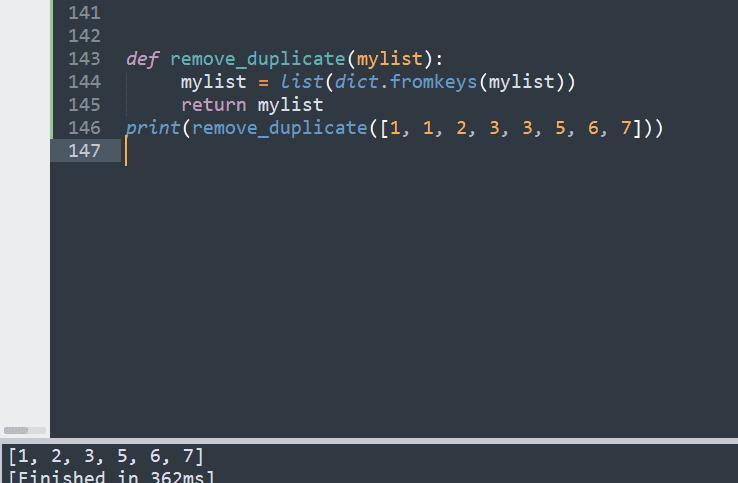
The code that remove duplicate is as follows:
def remove_duplicate(mylist):
mylist = list(dict.fromkeys(mylist))
return mylist
print(remove_duplicate([1, 1, 2, 3, 3, 5, 6, 7]))
<h3>Code explanation</h3>
The code is written in python.
- we defined a function named "remove_duplicate" and it accept the parameter "mylist".
- The variable "mylist" is used to store the new value after the duplicate vallues has been removed.
- Then, wed returned mylist.
- Finally, we call the function with the print statement . The function takes the required parameter.
learn more on python here: brainly.com/question/21126936
Answer:
When you are working with substrings in python you should treat the strings as lists, according to your answer the corrected code is given below:
sentence = "This is a possible value of sentence."
secondWord = sentence[sentence.find(" ")+1:]
secondWord = secondWord[0:secondWord.find(" ")]
print(secondWord)
Explanation:
#Define the value of the sentence for testing
sentence = "This is a possible value of sentence."
#Define a variable temp that starts when a blank space is find in the sentence to the end, sentence[n:] --> means everything in string after index "n"
temp = sentence[sentence.find(" ")+1:]
#Define the secondWord variable, you start at index 0 because in temp we already delete the first word and ends when finds the other blank space.
secondWord = temp[0:temp.find(" ")]
print(secondWord)
total = 0
for x in range(3, 67, 3):
total += x
print(total)
I hope this helps!