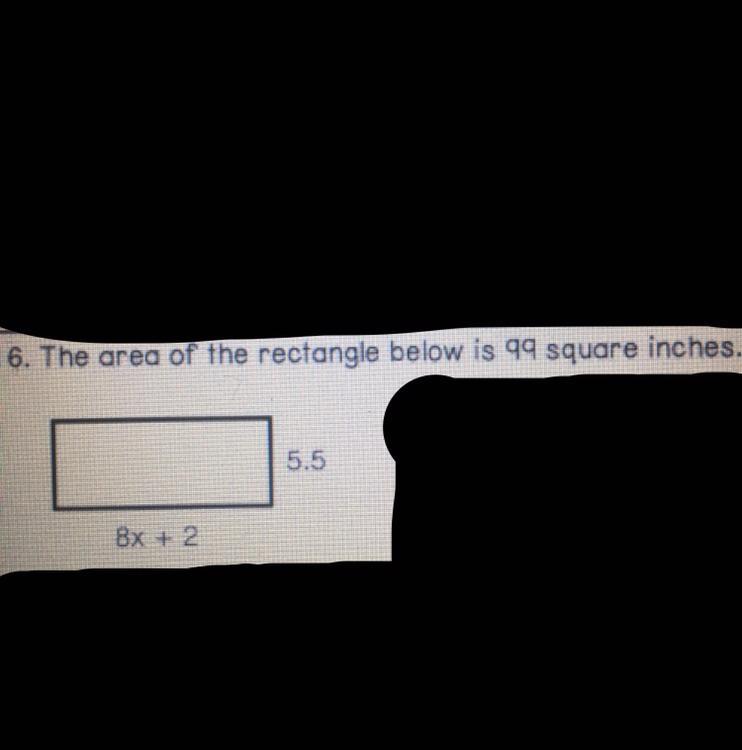
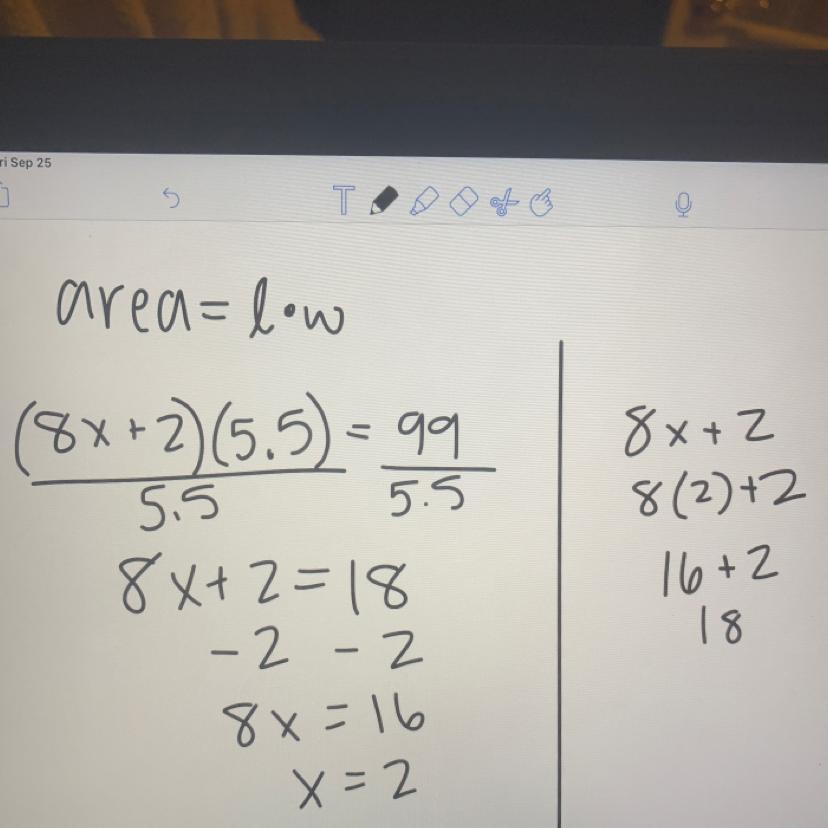Answer:
The standard deviation of the residuals calculates how much the data points spread around the regression line. The result is used to measure the error of the regression line's predictability.
Step-by-step explanation:
<h2>How do you find the standard deviation around the regression line?</h2>
STDEV. S(errors) = (SQRT(1 minus R-squared)) x STDEV. S(Y). So, if you know the standard deviation of Y, and you know the correlation between Y and X, you can figure out what the standard deviation of the errors would be be if you regressed Y on X.
<h2>What does standard deviation tell you?</h2>
A standard deviation (or σ) is a measure of how dispersed the data is in relation to the mean. Low standard deviation means data are clustered around the mean, and high standard deviation indicates data are more spread out.
Answer:
I wish I could help you but I havent learned any of that.
Step-by-step explanation:
Answer: √
145 or 12.04159457 for the decimal ways try 12
Step-by-step explanation: 12.0415945787923
Midpoint (−2,−9.5)
Slope −0.0833333333333333
x intercept −116.00
y intercept −9.67
Point A would be zero; Point B, the end of the 1/2-hour time interval, would be 1/2 (representing 1/2 hour). Then Amy needs to subdivide the interval A to B into three equal time intervals and to determine the length of each of these subintervals.
I would begin with 1/2 and divide that by 3:
1
--
2
====
3
--
1
Inverting the fraction in the denom. and multiplying, we get
1 1 1
-- * ---- = -----
2 3 6
So Amy will spend 1/6 th of an hour, or 10 minutes, on each chore.
Note that 3 times 1/6 comes out to 1/2 (hour), which is were we started.
The price of each item is $1.37.