Answer:
$1.75
Step-by-step explanation:
Honestly, you don't really have to pay attention to the other numbers or ratios on the graph until you think you found your answer. Pay attention to whichever ratio you choose and follow these steps:
1. Identify which number is the cost and which is the amount of pens bought
2. Set it up as a division problem by using the cost and the dividend and the amount of pens as the divisor
3. After you have your answer, plot your ratio of 1:(your product) and if the line that was graphed is straight, you are correct.
PS. I used the ratio (2:3.5) to solve this problem
False a number thta goes on without bounds is irrational
Answer:
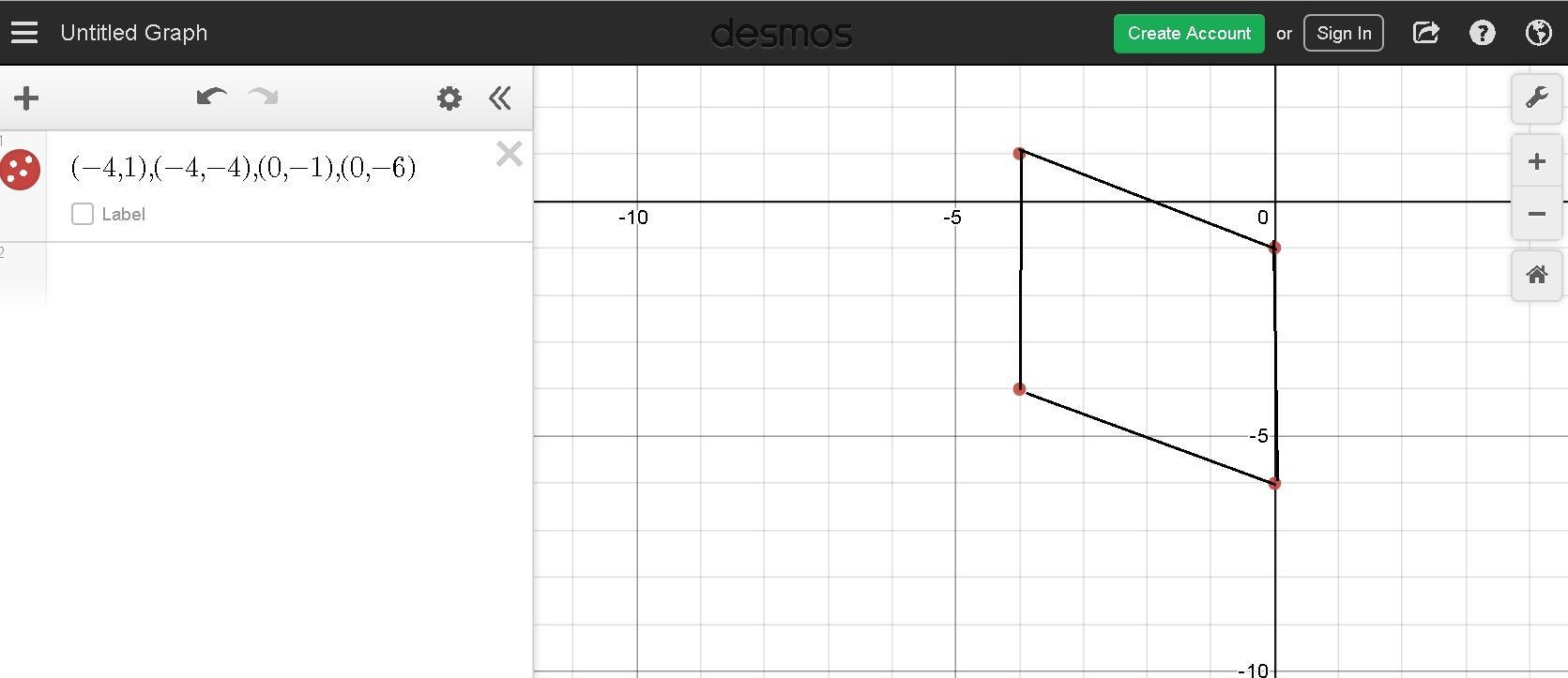
The shape is a quadrilateral
Step-by-step explanation:
we have

Using a graphing tool
Plot the figure
see the attached figure
we know that
A quadrilateral is a four-sided two-dimensional shape
Additionally the opposite sides of the figure are parallel and equal in length
so
Is a parallelogram too
Answer:
Step-by-step explanation:
its A