Answer:
C. Inside its PPC
Explanation:
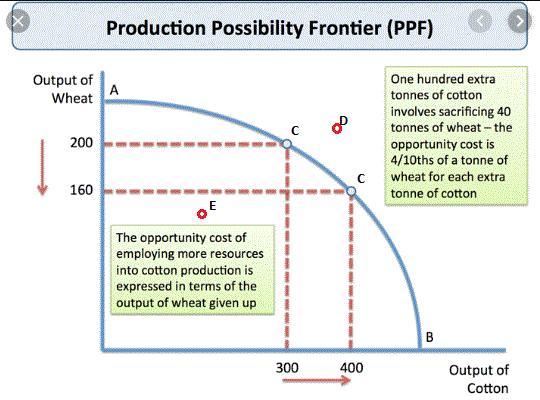
The Production possibility Curve also known as Production Possibility Frontier PPF is the curve that depict the relationship in the production of 2 given goods in an economy (See Image).
The curve basically shows 5 situations:
1. Point A: where all the production is devoted to Wheat
2. Point B: where all the production is devoted to Cotton
3. Points C: Any given point along the curve different to point A and B represent the trade off in the production of the 2 goods
4. Point D: Is an impossible point to achieve as it is outside the capabilities of the curve
5. Point E: Is an inefficient point of production as it is below the possibilities of production.
In the case of the expantion of the production capacity while the total spending fails to rise as fast. Then, the economy ends up in point E were inefficiency must be solve in order to produce in a maximum capacity.
<span>the type of risk that is most likely to be insurable is : A. pure risk
Pure risk refer to the type of risk in which loss is the only possible outcome.
Example of pure risk : Identitiy theft
Identity theft is insurable because the only possible outcome of identity theft is a loss in assets, there is no way someone could get more wealth after identity theft</span>
It shows a pattern of responsibility.
If you have only had accounts for 1 month, it doesn't really give a full picture of whether or not you always make your payments on time, etc. However if you have had accounts for 20 years, creditors have more history to look through to determine if you are responsible.
Keep in mind, checking and savings accounts are not the primary type of accounts that creditors want to look at because those only deal with spending money you already have. Lenders really want to know how you handle money that you <em>borrow</em>, such as school loans, credit cards, rent payments, and auto loans.