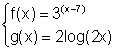Answer:
x = 7.791
Step-by-step explanation:
Given :


Solution : since we are given that we have to use technology for finding the solution to the given system of equations
So, we will use desmos calculator to find the solution .
The intersecting point of given two equations will be the solution of this system of equation .
So, by putting given equations in desmos calculator we get the resultant figure (attached figure).
Blue line shows the graph of equation
Red line shows the graph of equation
Now we can see in the figure the intersecting point is (7.791,2.385)
So, the x coordinate i.e. 7.791 is the solution of system of equation