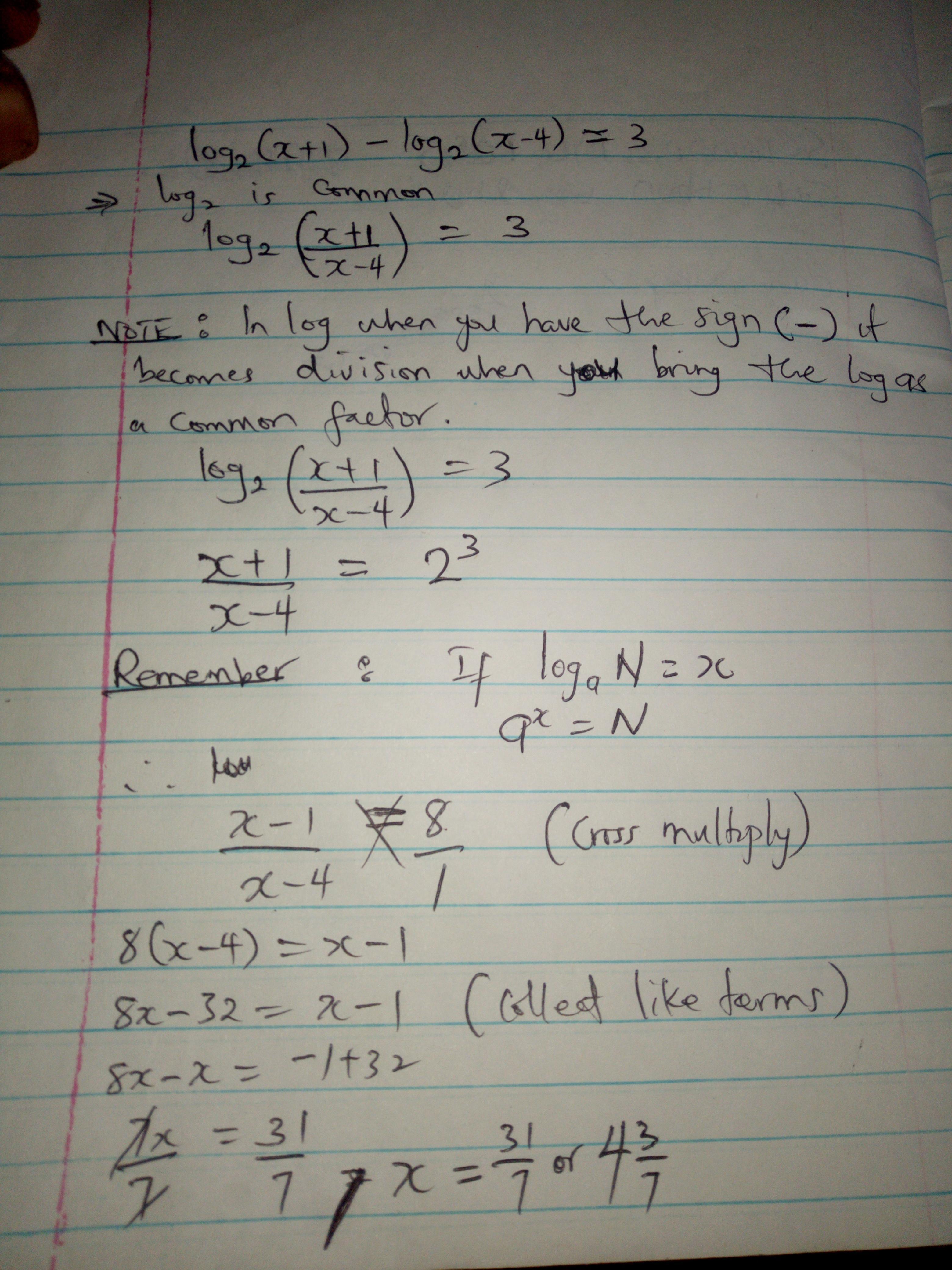Answer:
31/7
Step-by-step explanation:
Check attachment
Answer:
2
Step-by-step explanation:
0Answer:
1) Exterior Angle Therorem
2) Isosceles Triangle Theorem
Step-by-step explanation:
factor out 8a from the expression 8a(5a-4)
By using a change of units, we can see that the rate in dollars per liter is:
R = $0.0027 per liter.
<h3>
How to convert the rate?</h3>
Here we have a rate in dollars per cubic foot, and we want to rewrite this in dollars per liter. So we just need to apply a change of units.
The original rate is in dollars per square foot, and it is given by:
R = $1.30 for 16.7ft^3
We know that the relation between cubic feet and liters is:
1ft^3 = 28.32 L
Then, if we apply a change of units, we can rewrite the volume as:
16.7ft^3 = 16.7*(28.32) L = 472.9 L
Then the rate is $1.30 per 472.9 L, taking the quotient we get:
R = ($1.30/472.9 L) = $0.0027 per liter.
If you want to learn more about changes of units:
brainly.com/question/9032119
#SPJ1