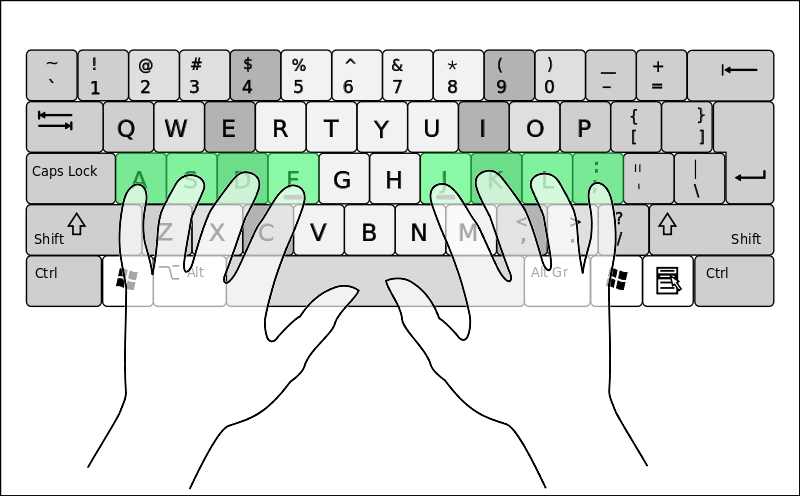
C) A, S, D, F, G, H, J, K, L
The home row of keys are the keys which are in the middle of the keyboard. F and J have little bumps on them, which signify that they are the home keys. The home row is also where your fingers are meant to return when not typing.
Answer:
problem-solving
Explanation:
he is making sure all his problems have been resolved before starting a new shift.
Answer:
Types of Motherboard
Explanation:
Motherboards are present in Desktop, Laptop, Tablet, and Smartphone and the components and functionalities are the same. But the size of the components and the way they are accommodated on the board varies due to space availability. In desktops, most of the components are fitted inside the sockets provided on the board and it is easy to replace each of them separately, whereas in Laptops/Smartphones some components are soldered on the board, hence it is difficult to replace/upgrade.
Though different motherboards have varying capabilities, limitations, features, Physical size/shapes (form factor), they are identified/grouped/categorized mostly by their form factors. Each manufacturer has come out with its form factor to suit the design of computers. Motherboard manufactured to suit IBM and its compatible computers fit into other case sizes as well. Motherboards built using ATX form factors were used in most of the computers manufactured in 2005 including IBM and Apple.
Answer:
The answer to this question is given below in the explanation section.
Explanation:
Almost all app that is doing online business integrated third party payment gateway and login/services. But some apps, don't integrate the third party login/signin services such as go ogle or face book login/sign in services.
But in the context of this question, for a parking payment app, upon reservation of parking space, the pay option connects a user to a third party/external gateway. This gateway will accept payment from the user and upon confirmation of payment, the parking space will get reserved.
so the correct option to this question is:
While the other options are incorrect because:
The sign-in option does not connect the user to a third pay/gateway in case if the app has self-registration and sign-in functionality. Rate and Time remaining are features of the app that does not force the user to connect third-party gateway.
Answer:
It is important to note that the primary purpose of EHRs is to support and improve individual patient care. As such the EHR is created and held according to professional and legal obligations of confidentiality
Explanation: