Answer:
I am writing a Python program. Let me know if you want the program in some other programming language.
import string #to use string related functions
def wordcount(filename): # function that takes a text file name as parameter and returns the number of occurrences of every word in file
file = open(filename, "r") # open the file in read mode
wc = dict() # creates a dictionary
for sentence in file: # loop through each line of the file
sentence = sentence.strip() #returns the text, removing empty spaces
sentence=sentence.lower()
#converts each line to lowercase to avoid case sensitivity
sentence = sentence.translate(sentence.maketrans("", "", string.punctuation)) #removes punctuation from every line of the text file
words = sentence.split(" ") # split the lines into a list of words
for word in words: #loops through each word of the file
if len(word)>2: #checks if the length of the word is greater than 2
if word in wc: # if the word is already in dictionary
wc[word] = wc[word] + 1 #if the word is already present in dict wc then add 1 to the count of that word
else: #if the word is not already present
wc[word] = 1 # word is added to the wc dict and assign 1 to the count of that word
for w in list(wc.keys()): #prints the list of words and their number of occurrences
print(w, wc[w]) #prints word: occurrences in key:value format of dict
wordcount("file.txt") #calls wordcount method and passes name of the file to that method
Explanation:
The program has a function wordcount that takes the name of a text file (filename) as parameter.
open() method is used to open the file in read mode. "r" represents the mode and it means read mode. Then a dictionary is created and named as wc. The first for loop, iterates through each line (sentence) of the text file. strip() method is used to remove extra empty spaces or new line character from each sentence of the file, then each sentence is converted to lower case using lower() method to avoid case sensitivity. Now the words "hello" and "Hello" are treated as the same word.
sentence = sentence.translate(sentence.maketrans("", "", string.punctuation)) statement uses two methods i.e. maketrans() and translate(). maketrans() specifies the punctuation characters that are to be deleted from the sentences and returns a translation table. translate() method uses the table that maketrans() returns in order to replace a character to its mapped character and returns the lines of text file after performing these translations.
Next the split() method is used to break these sentences into a list of words. Second for loop iterates through each word of the text file. As its given to ignore words of length 2 or less, so an IF statement is used to check if the length of word is greater than 2. If this statement evaluates to true then next statement: if word in wc: is executed which checks if the word is already present in dictionary. If this statement evaluates to true then 1 is added to the count of that word. If the word is not already present then the word is added to the wc dictionary and 1 s assigned to the count of that word.
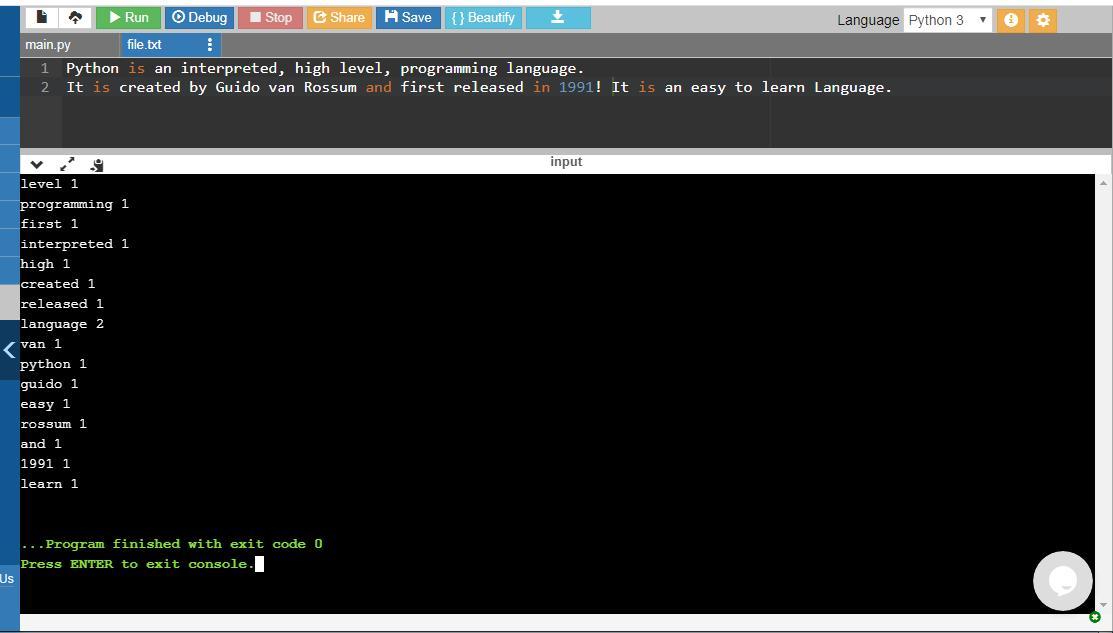
Next the words along with their occurrences is printed. The program and its output are attached as screenshot. Since the frankenstein.txt' is not provided so I am using my own text file.