I say b because if you use a camera strap then you won't drop the camera on the hard ground.
On a Linux system, the first daemon that is loaded is known as init.
<h3>What is a
daemon?</h3>
A daemon can be defined as a program that is designed and developed to run continuously and it's created to handle periodic service requests that are expected to be received on a computer system such as a Linux system.
On a Linux system, init simply refers to the first daemon that is loaded and it runs continuously.
Read more on Linux here: brainly.com/question/25480553
#SPJ12
Answer:
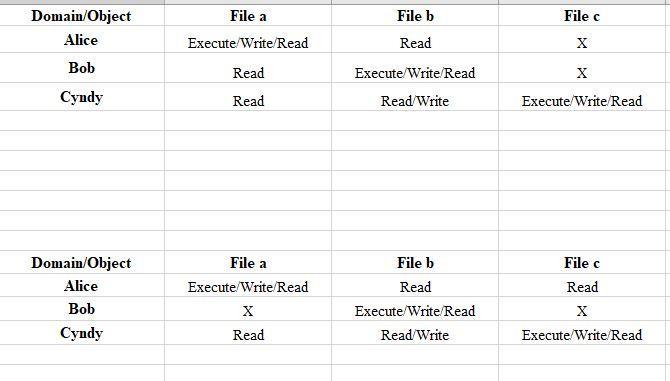
answered in Image and explanation is given below.
Explanation:
CL is euqal to user permission on every file
ACL is equal to how permissions are defined for one life for example File a, read, write, execute.
Answer:
tldr; treat this like a brief essay. some reasons would be "having a smartphone makes your job easier", "smartphones can make the job easier to do on the go".
Explanation:
hi there!
ok, so this should be pretty simple. first, we should take a look at the issue in the scenario; you're an employee for a company that relies heavily on technology to get your job done and send other employees to their customer's locations. because of this, getting poor quality mobile phones would make your job a little bit harder to do.
to put this in a little bit of a better perspective, imagine that you're an employee in a store, and your job is to sweep the floor. however, your boss only gives you a dust pan and bad quality broom. that'd make you wish that you had some better equipment to get your job done faster, right?
a memo is basically a written message in a business place; in modern days, they're usually emails, but back in the day they were letters and such. for this assignment, treat this like an essay! however, be sure to be to-the-point.
now to answer the question; we've already covered one reason that you could use in the memo: "having a smartphone would make your job easier". now think about what else having a smartphone would do compared to a mobile company phone.
here's an example of a memo!
good luck! hope this helped.
Answer:
<u>Pseudocode:</u>
INPUT velocity
INPUT time
SET velocity = 0.44704 * velocity
SET acceleration = velocity / time
SET acceleration = round(acceleration, 1)
PRINT acceleration
<u>Code:</u>
velocity = float(input("Enter a velocity in miles per hour: "))
time = float(input("Enter a time in seconds: "))
velocity = 0.44704 * velocity
acceleration = velocity / time
acceleration = round(acceleration, 1)
print("The acceleration is {:.2f}".format(acceleration))
Explanation:
*The code is in Python.
Ask the user to enter the velocity and time
Convert the miles per hour to meters per second
Calculate the acceleration using the formula
Round the acceleration to one decimal using round() method
Print the acceleration with two decimal digits