Answer:
a)
Therefore to compare this data effectively using the rates per driver is better off like for people who do not smoke their rate will be = 59 / 452 = 13.1% while for smokers of 61+ times = 50 / 156 = 32.1% and this rate will show clearly tat more accidents where caused by people who smoked 51+ times hence it should be used for graphical representation
b) attached below
Step-by-step explanation:
A) A useful graph is must compare rates rather than counts of accidents in the four marijuana use classes
Using the rates on a graph is better for reference like saying; that 50 crashes were caused by those who smoke 51+ times and 59 crashes is caused by those who never smoke this statistics makes it seem like smoking has no effect on the amount of accidents
Therefore to compare this data effectively using the rates per driver is better off like for people who do not smoke their rate will be = 59 / 452 = 13.1% while for smokers of 61+ times = 50 / 156 = 32.1% and this rate will show clearly tat more accidents where caused by people who smoked 51+ times hence it should be used for graphical representation
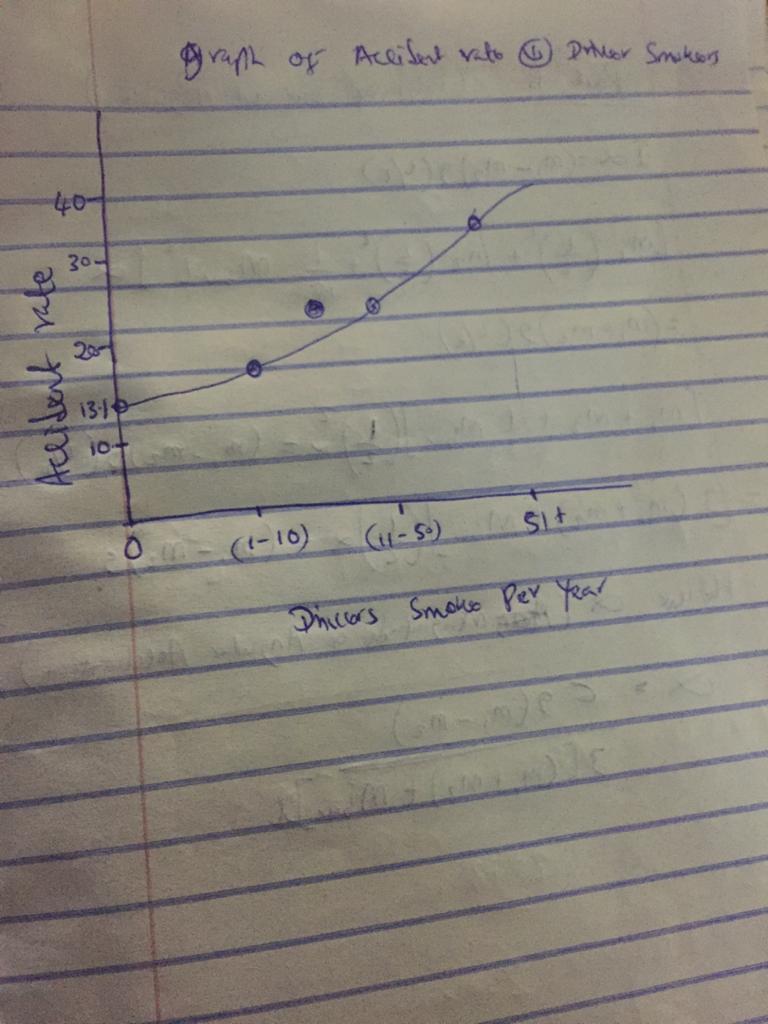
B) accident rate for Non-smokers
= (59/452) * 100 = 13.05
accident rate for smokers between 1-10 times
= ( 36/ 229 ) * 100 = 15.72
accidents rate for smokers between 11 - 50 times
= ( 15/50 ) * 100 = 21.42
accidents rate for smokers 51+
= ( 50 / 156 ) * 100 = 32.05
attached below is the required graph
Answer:
she rode 6.6 miles per hour
at that rate she would travel 36 miles in 5 hours, 27 minutes, 16 seconds.
Answer:
D. 6
Step-by-step explanation:
Here we are given that a sample of 256 was taken from a population with a standard deviation of 96 centimeters i.e.  = 96 and n = 256.
= 96 and n = 256.
And we have to calculate the margin of error for a 68% confidence interval.
Firstly from z score% table we observe that at 32% level of significance the z score critical value is given by 0.99744 .
<em>And Margin of error formula is given by ;</em>
 *
*  = 0.99744 *
= 0.99744 *  = 5.98
= 5.98
Approximately, we get Margin of error = 6.
Answer: A graphical display of data using different heights