Answer:
1. True: Naive Bayes is a linear classifier.
2. False: SVMs are only usable when the classes are linearly separable in the feature space.
3. False: Adding training data always results in a monotonic increase in the accuracy of a Naive Bayes classifier.
4. True: When sufficient data is available, SVMs generally perform as well or better than other common classifiers such as KNN.
5. False: With enough training data, the error of a nearest neighbor classifier always goes down to zero.
Explanation:
Naive Bayes is a linear classifier that leads to a linear decision boundary. It can be applied to a linearly separable problems and when the elements are independent i.e the occurrence of an element doesn't affect the occurrence of another. It can be used for making multi class predictions in artificial intelligence.
The Support Vector Machine (SVM) on the other hand, can either be a non-linear classifier (with RBF kernel) or a linear classifier (with linear kernel). It maximizes the margin of a decision boundary in its mode of operation.
Hence, the SVMs can be used for regression or classification problems.
For example, determining whether an e-mail is a spam or not.
Answer:
- with(open("numbers.txt")) as file:
- data = file.readlines()
- runsum = 0
- largest = 0
-
- for x in data:
- if(int(x) > largest):
- largest = int(x)
- runsum += largest
-
- print(runsum)
Explanation:
The solution code is written in Python 3.
Firstly, open a filestream for numbers.txt (Line 1) and then use readlines method to get every row of data from the text files (Line 2).
Create a variable runsum to hold the running sum of number bigger than the maximum value read up to that iteration in a for loop (Line 3).
Use a for loop to traverse through the read data and then check if the current row of integer is bigger than the maximum value up to that point, set the current integer to largest variable and then add the largest to runsum (Line 6 - 9).
At last display the runsum to console terminal (Line 11).
Since both arrays are already sorted, that means that the first int of one of the arrays will be smaller than all the ints that come after it in the same array. We also know that if the first int of arr1 is smaller than the first int of arr2, then by the same logic, the first int of arr1 is smaller than all the ints in arr2 since arr2 is also sorted.
public static int[] merge(int[] arr1, int[] arr2) {
int i = 0; //current index of arr1
int j = 0; //current index of arr2
int[] result = new int[arr1.length+arr2.length]
while(i < arr1.length && j < arr2.length) {
result[i+j] = Math.min(arr1[i], arr2[j]);
if(arr1[i] < arr2[j]) {
i++;
} else {
j++;
}
}
boolean isArr1 = i+1 < arr1.length;
for(int index = isArr1 ? i : j; index < isArr1 ? arr1.length : arr2.length; index++) {
result[i+j+index] = isArr1 ? arr1[index] : arr2[index]
}
return result;
}
So this implementation is kind of confusing, but it's the first way I thought to do it so I ran with it. There is probably an easier way, but that's the beauty of programming.
A quick explanation:
We first loop through the arrays comparing the first elements of each array, adding whichever is the smallest to the result array. Each time we do so, we increment the index value (i or j) for the array that had the smaller number. Now the next time we are comparing the NEXT element in that array to the PREVIOUS element of the other array. We do this until we reach the end of either arr1 or arr2 so that we don't get an out of bounds exception.
The second step in our method is to tack on the remaining integers to the resulting array. We need to do this because when we reach the end of one array, there will still be at least one more integer in the other array. The boolean isArr1 is telling us whether arr1 is the array with leftovers. If so, we loop through the remaining indices of arr1 and add them to the result. Otherwise, we do the same for arr2. All of this is done using ternary operations to determine which array to use, but if we wanted to we could split the code into two for loops using an if statement.
Answer:
b) 01564 37928
e) 26 8 75 32 901
Explanation:
Pushes and pulls are the computer operations which enable the user to perform numerical tasks. The input commands are interpreted by the computer software and these tasks are converted into numeric values to generate output.
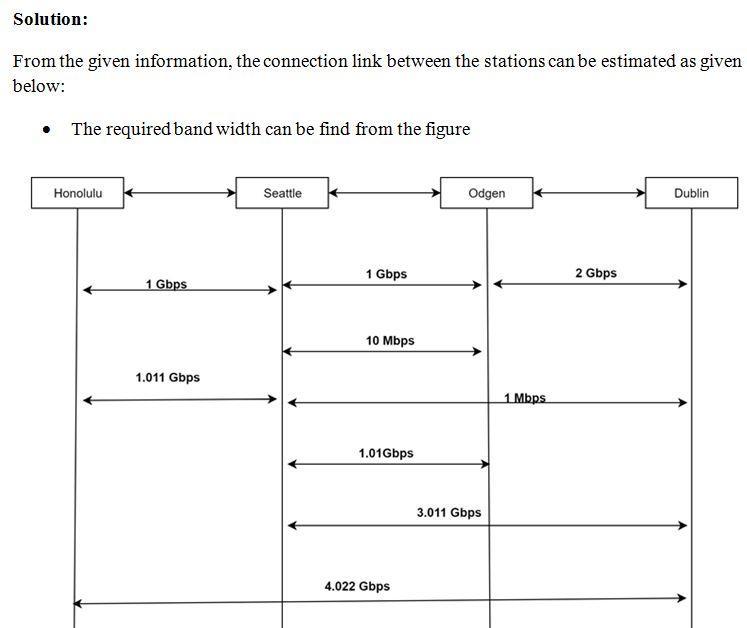
Answer:
See explaination
Explanation:
Looking at telecommunications network, a link is a communication channel that connects two or more devices for the purpose of data transmission. The link is likely to be a dedicated physical link or a virtual circuit that uses one or more physical links or shares a physical link with other telecommunications links.
Please check attachment for further solution.