U paste it the u press enter
The SQL statement that would create the GET_CREDIT_LIMIT procedure to obtain the full name and credit limit of the customer is:
GET_CREDIT_LIMIT
SELECT CUST_ID 125
FROM FIRST_NAME, LAST_NAME, CREDIT_LIMIT
WHERE LAST_NAME ="Smith"
<h3>What is SQL?</h3>
This is an acronym that means Structured Query Language that is used in handling data in a database.
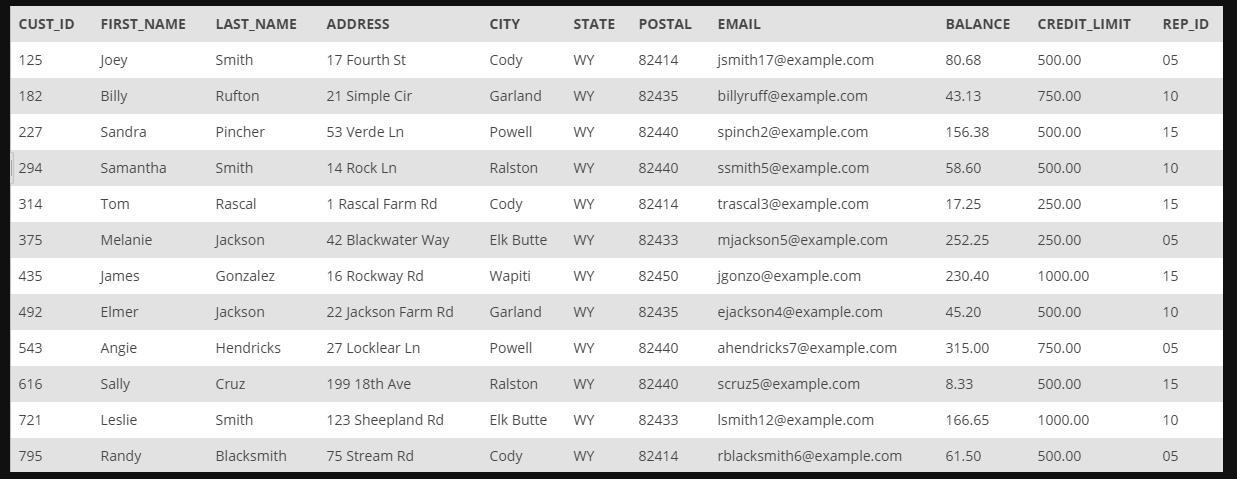
Hence, we can see that from the attached image, there is a table that contains the details of customers and their various data such as their first and last names, credit limits, address, etc, and the GET_CREDIT_LIMIT procedure is shown above.
Read more about SQL here:
brainly.com/question/25694408
#SPJ1
Answer:
JList.setSelectionMode(ListSelectionModel.MULTIPLE_INTERVAL_SELECTION)
Explanation:
JList provides for simultaneous selection of multiple items upon setting the selection mode to MULTIPLE_INTERVAL_SELECTION. The API call for this purpose is:
jlist.setSelectionMode(ListSelectionModel.MULTIPLE_INTERVAL_SELECTION)
Once the selection mode has been set , we can select set of items in the list as follows:
jlist.setSelectedIndices({1,3,5});
This will select the items with indices 1,3,5 in the list.