Answer:
True
Explanation:
In most accounting software like SAP, Application control performs what is known as validity check.
And Validity check is when this application control compares the data entered into a field for a transaction to that in a master record to verify the data entered exists.
With above definition we can infer that the question statement is true.
Answer:
2.
Explanation:
working with other people can increase ones creativity
Answer:
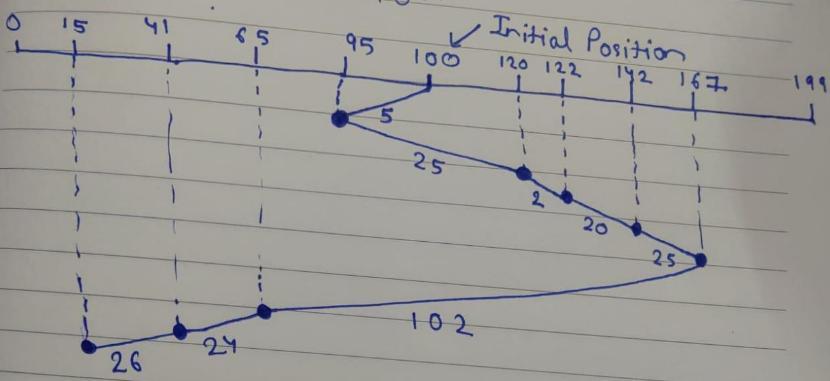
follows are the solution to the given question:
Explanation:
Please find the image file for the SSTF scheduling algorithm.
Following are the requested order:

Calculating the Total Head Movement:

Answer:
libraries do this so that you dx chae
Explanation:
Answer:
A. Your road is paved and the crossroad is not
Explanation: