Answer:
The standard deviation of the residuals calculates how much the data points spread around the regression line. The result is used to measure the error of the regression line's predictability.
Step-by-step explanation:
<h2>How do you find the standard deviation around the regression line?</h2>
STDEV. S(errors) = (SQRT(1 minus R-squared)) x STDEV. S(Y). So, if you know the standard deviation of Y, and you know the correlation between Y and X, you can figure out what the standard deviation of the errors would be be if you regressed Y on X.
<h2>What does standard deviation tell you?</h2>
A standard deviation (or σ) is a measure of how dispersed the data is in relation to the mean. Low standard deviation means data are clustered around the mean, and high standard deviation indicates data are more spread out.
There has to be something in between the two numbers, for example 7 x 7 or 7+7 not just 7 7. Without the equation it would be highly impossible to answer :D
The first letter can be any one of 8. For each of those . . .
The second letter can be any one of the remaining 7. For each of those . . .
The third letter can be any one of the remaining 6. For each of those . . .
The fourth letter can be any one of the remaining 5. For each of those . . .
The fifth letter can be any one of the remaining 4.
The total number of possibilities is (8 x 7 x 6 x 5 x 4) = <em>6,720</em> .
(That's 8! / 3! .)
Note:
If you're allowed to use the same letter more than once,
then there are 8 choices for each of the 5 letters.
The total number of possibilities then is (8 x 8 x 8 x 8 x 8) = 32,768 .
(That's 8⁵ or 2¹⁵ .)
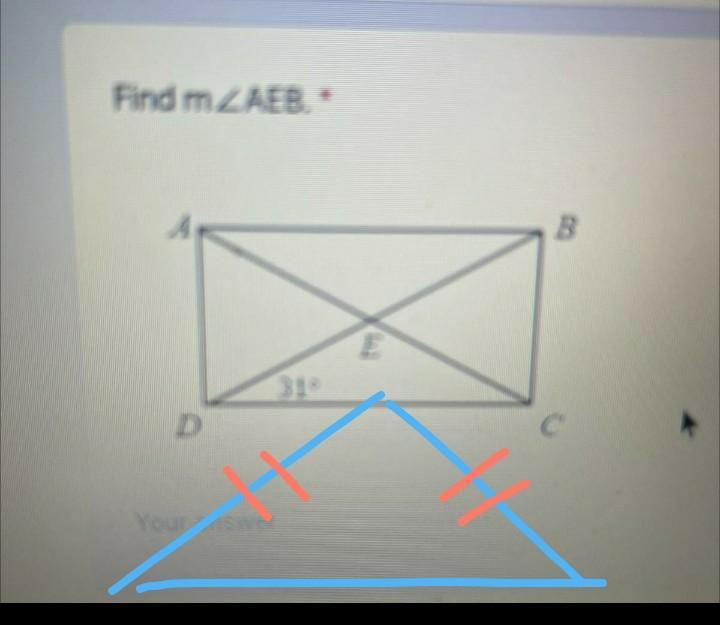
Answer:
118
Step-by-step explanation:
the length ED is equal to EC
so
the angle is also the same
that's mean the angle ECD is equal to 31
then to find the another angle just do like this
=180–31–31
=118