Answer:

So then the best option would be:
a. 1/25
Step-by-step explanation:
For this case we assume that the sample space for the numbers is :
![S_1= [A,B,C,D,E]](https://tex.z-dn.net/?f=%20S_1%3D%20%5BA%2CB%2CC%2CD%2CE%5D)
And the sample space for the numbers is:
![S_2 =[1,2,3,4,5]](https://tex.z-dn.net/?f=%20S_2%20%3D%5B1%2C2%2C3%2C4%2C5%5D)
Both sampling spaces with a size of 5.
We define the following events:
A="We select a 2 from the numbers"
B= "We select a E from the letters"
We can find the individual probabilities for each event like this:


And assuming independence we can find the probability required like this:
The last probability is the probability of obtain obtain a 2 AND an E
So then the best option would be:
a. 1/25
Answer:
The hypothesis test is right-tailed and the parameter that is being tested is the population standard deviation ( ).
).
Step-by-step explanation:
We are given with the following null and alternative hypothesis below;
Null Hypothesis, 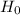 : = 7
: = 7
Alternate Hypothesis,  : > 7
: > 7
The parameter that is being tested here is the population standard deviation (). So, the null hypothesis states that the population standard deviation is equal to 7 while on the other hand, the alternate hypothesis states that the population standard deviation is greater than 7.
The above hypothesis test is right-tailed because in the alternate hypothesis, greater than sign is there which means that if the test statistics will be more than the critical value, then the null hypothesis will be rejected.
Tan (10 degrees) = 1983 / distance
distance = 1983 / tan (10 degrees)
distance = 1983 / 0.17633
<span><span><span>distance = 11,246</span> feet
11,246 / 5,280 = 2.13 miles</span> </span>