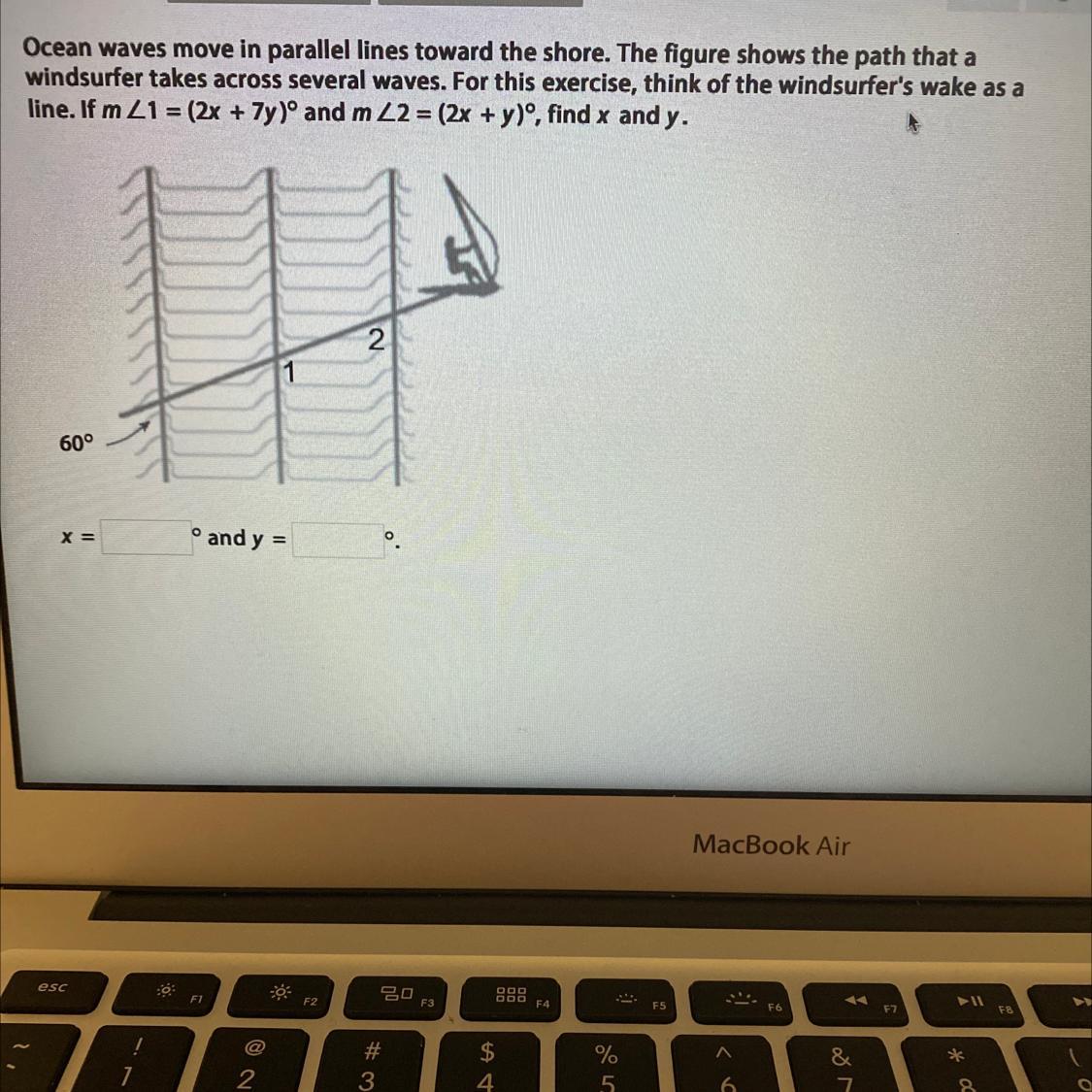
Answer:
x = 10
y = 40
Step-by-step explanation:
60° + (2x + 7y)° = 180° because these two angles are supplementary
So 2x + y would be equal to 60°
60° + (2x + 7y)° = 180° subtract 60 from both sides
2x + 7y = 120 and
2x + y = 60 multiply second equation by -1 and it will be -2x -y = -60 now add it to first equation
2x + 7y -2x - y = 120 - 60 -2x will eliminate 2x
6y = 60 divide both sides by 6
x = 10
if 2x + y = 60 the we need to replace x with the value we found
2×10 + y = 60
y = 40