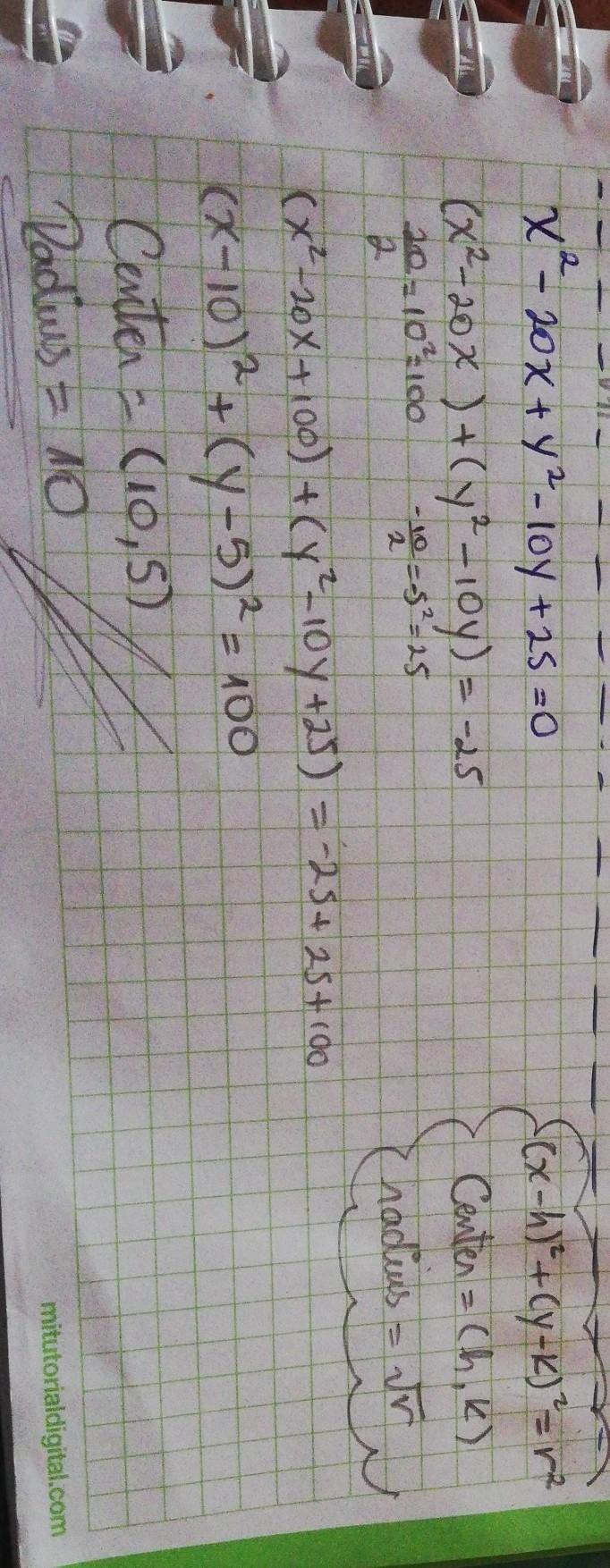Answer:
Center = (10, 5)
Radius = 10
Step-by-step explanation:
Look at the picture
Answer:
B. The nominal level of measurement is most appropriate because data cannot be ordered.
Step-by-step explanation:
Nominal scale is used when there is no specific order scale and data can be arranged according to name. Ordinal scale requires variables to be arranged in specific order. For fast food restaurant the best scale used is nominal scale as variables can be arranged according to their name without specific order.
Slope: (y2-y1)/(x2-x1)
(5+7)/(1-8) = 12/-7
Solution: the slope is -12/7
Remark
What the question is saying is that you are setting up a proportion. Ordinarily a child would require 125 mg be put into 5 mL of liquid. This child is special and only requires 100 mg. How many mL are needed?
Proportion
125 mg : 5 mL :: 100 mg: x
Solution
125 / 5 = 100 / x Cross multiply
125x = 500 Divide by 125
125x/125 = 500/125 Do the division
x = 4
Answer
100 mg would be put in 4 mL of liquid