C. Deleting temporary files
Answer:
Organizations need to change the vast majority of their tasks to the cloud to stay competitive describes the current Cloud landscape for business
Explanation:
All cloud computing frameworks are effectively open over the web with minimal requirement for actual equipment other than cloud servers at the back end.
Answer:
Explanation:
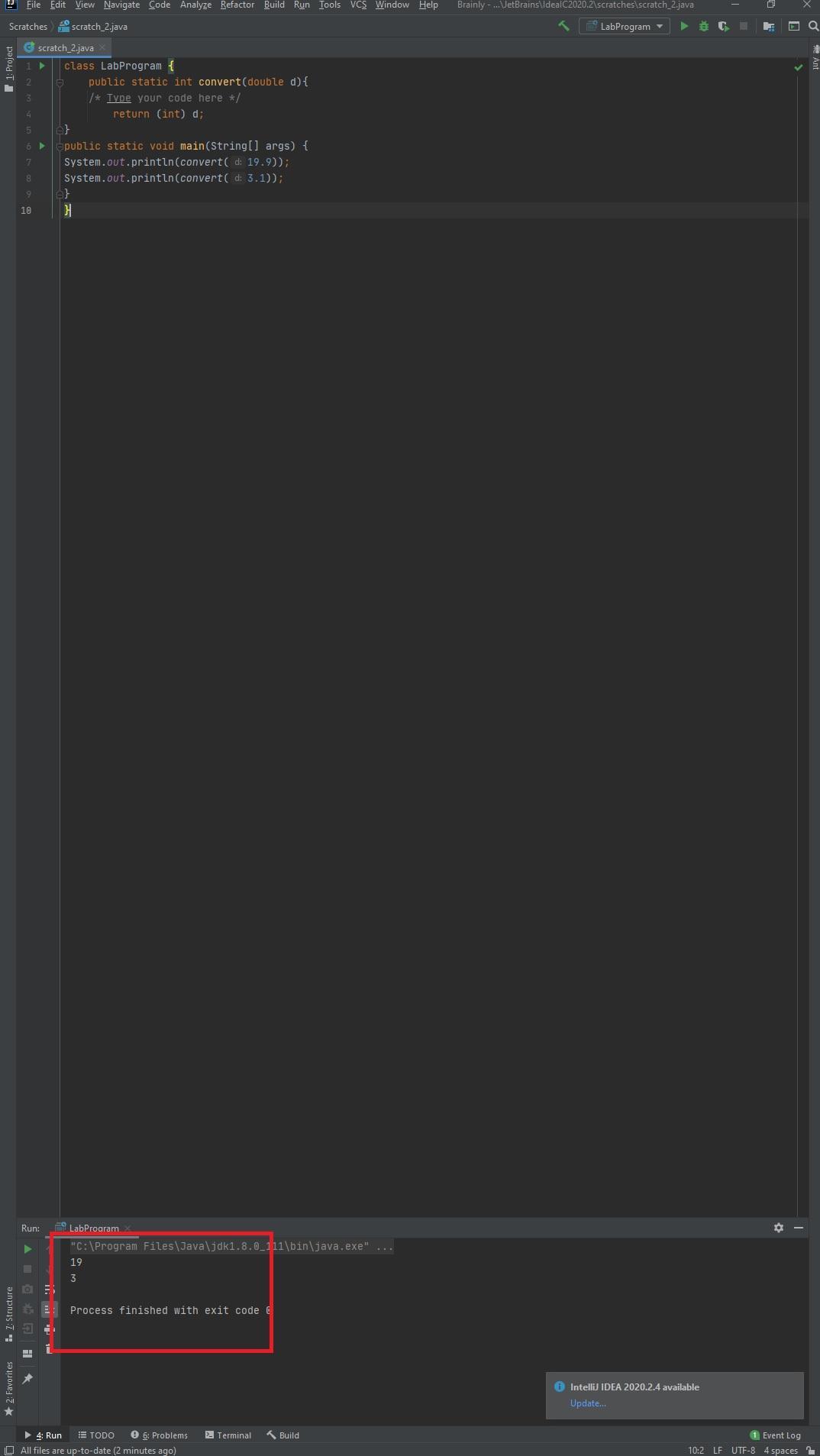
The code provided is written in Java. The statement is provided right under the /*Type your code here*/. In Java, in order to case one primitive to another you simply need to type the primitive type that you are trying to cast too before the variable and within parenthesis. The output of the new code can be seen in the attached image below.
class LabProgram {
public static int convert(double d){
/* Type your code here */
return (int) d;
}
public static void main(String[] args) {
System.out.println(convert(19.9));
System.out.println(convert(3.1));
}
}
Answer:
You don't need a birth certificate
Explanation: