Y - 3 = 5/3 (x - 0)
this is point slope
y - 3 = 5/3x
y = 5/3x + 3
Since real numbers are closed with respect to division (i.e. the division between two real numbers is again a real number), the fraction  is a real number everytime both m and n are real numbers.
is a real number everytime both m and n are real numbers.
In other words, you can choose any real number m and any real number n, and their ratio will still be a real number.
Of course, you have to follow the only rule that you can't divide by zero, so the answer is more precisely

Y=x-4
x=y+4
y=-3(y+4)
y=-3y-12
4y=-12
y=-3
x=1
The ratio in it's lowest form is 7:4
Answer:
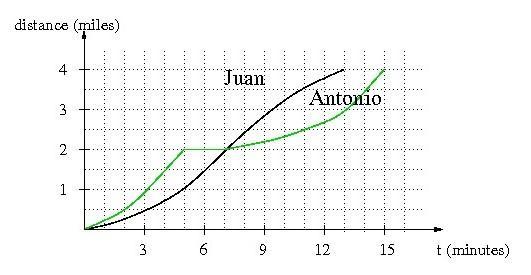
Juan wins the race
Step-by-step explanation:
<u>The graph is shown in attached image.</u>
<u />
The black line is Juan's graph.
The green line is Antonio's graph.
The graph shows the distance (y-axis) with time (x-axis).
The end of the curve(s) means the end of the race. Both curve's ending point in y-axis is 4 miles so the end of the race is 4 miles.
But in x-axis, we see the time:
Juan finishes at 13 minutes
Antonio finishes at 15 minutes
<u>Definitely Juan wins the race</u>