Ithe diameter would be about 5
Answer:
the hieght will be 58.10m
Step-by-step explanation:
Y=mx+b is our base equation
m=slope, so let's find that first:
m= change in y/change in x
So between the points (-1,-2) and (3,4),
The y values, -2 and 4, have a difference of 6. The x values, -1 and 3, have a difference of 4. This makes our slope 6/4 (or 3/2 simplified)
Now our equation is
Y=3/2x + b
We still need to find b
To find b, we can substitute a point given to us. Let's use (3,4) just to avoid negatives.
4=3/2(3) + b
Multiply
4=9/2 + b
Subtract 9/2 from both sides
-1/2=b
Now let's put it all back together!
Y=3/2x-1/2 Is the answer.
I hope this Helps!
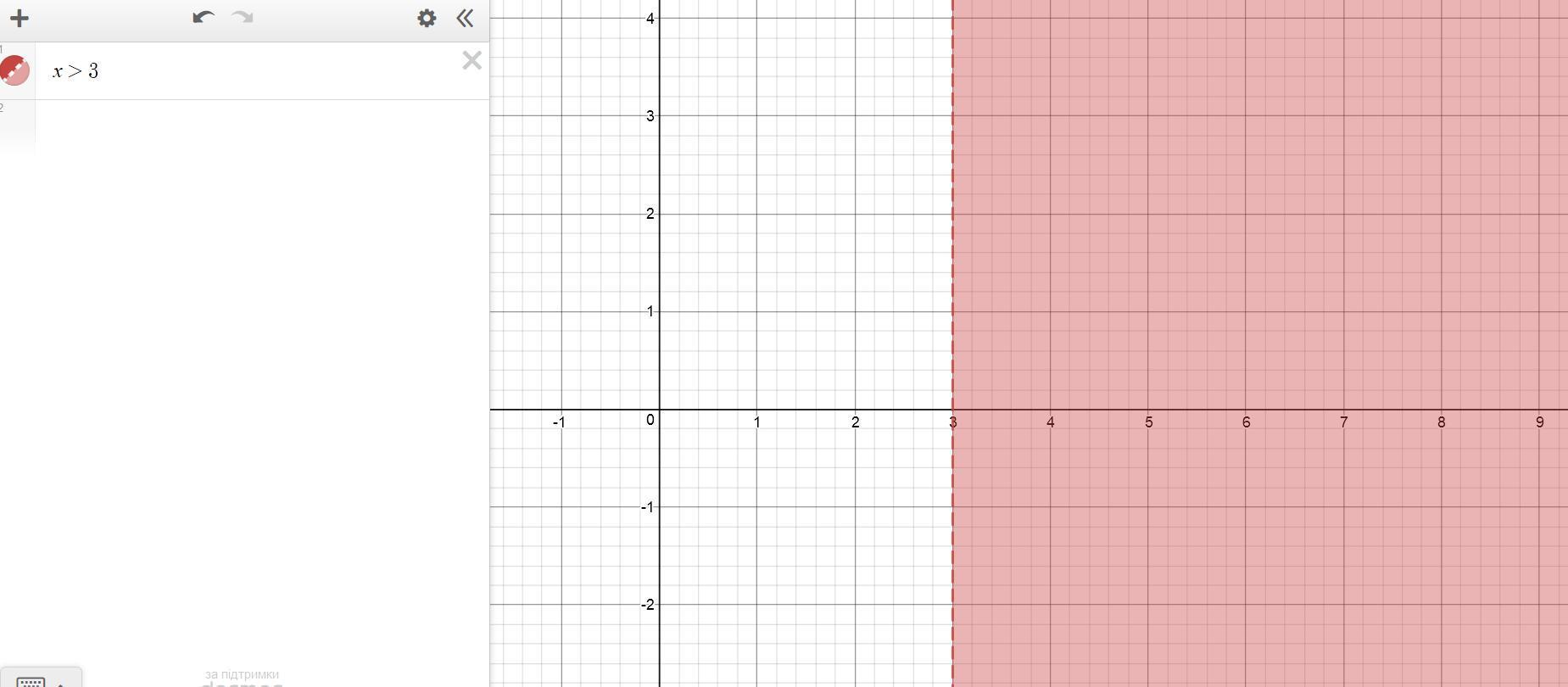
First simplify this inequality:

Now you can graph this inequality. Draw the vertical dashed line x=3 and shade the region to the right from this line. This is exactly the region that represents the solution of inequality (see attached diagram for details).
Answer:
1 ) a 2) b 3) d 4) b 5) a 6) c
Step-by-step explanation: