First Question is boolean,
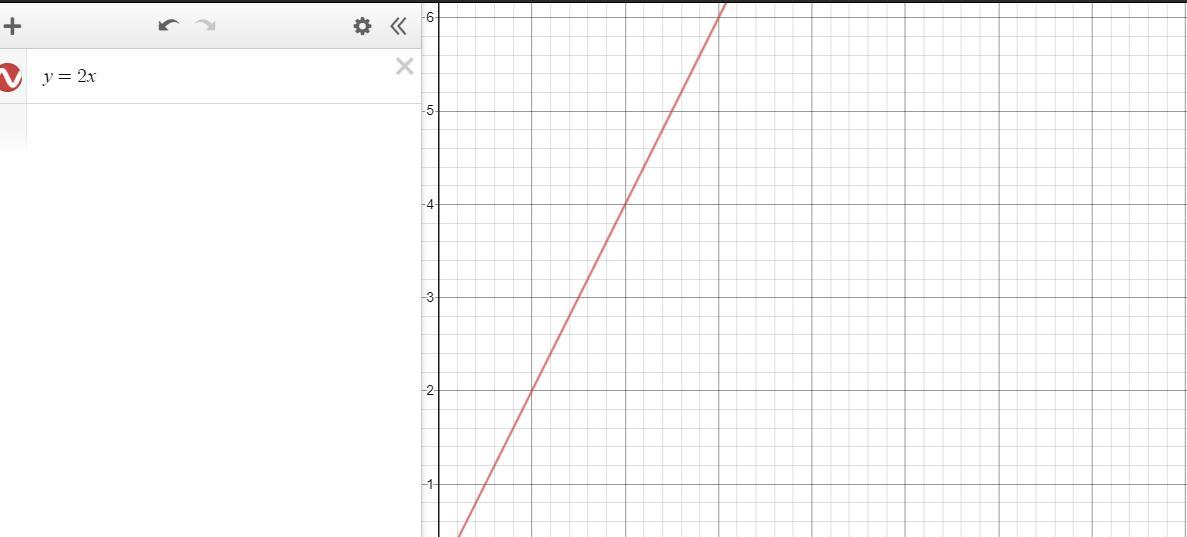
Question 35 is probably floating point ,
Question 36 is probably an integer, since it shows 1, 2, 3, and 1, 2, 3 are not fractions, and integers are whole numbers.
Im not 100% sure but I hope I helped,
Have a nice day/night :)
Answer:
this is what i found hope it helps
Multiply to remove the variable from the denominator.
x = − 3/40y
Answer:
cake
Step-by-step explanation:
work but i dont think i should tell you but if you put me on brainlyest ill sure te hvycgv gy8hhn bjvhfn vbn ggv6yxdf mb
Answer:
3
Step-by-step explanation:
Since the shapes are similar this means they are equal.
If the ratio is 2:1 that would mean divide each number by 2.
6/2 reduced equals 3/1 = 3
Answer:
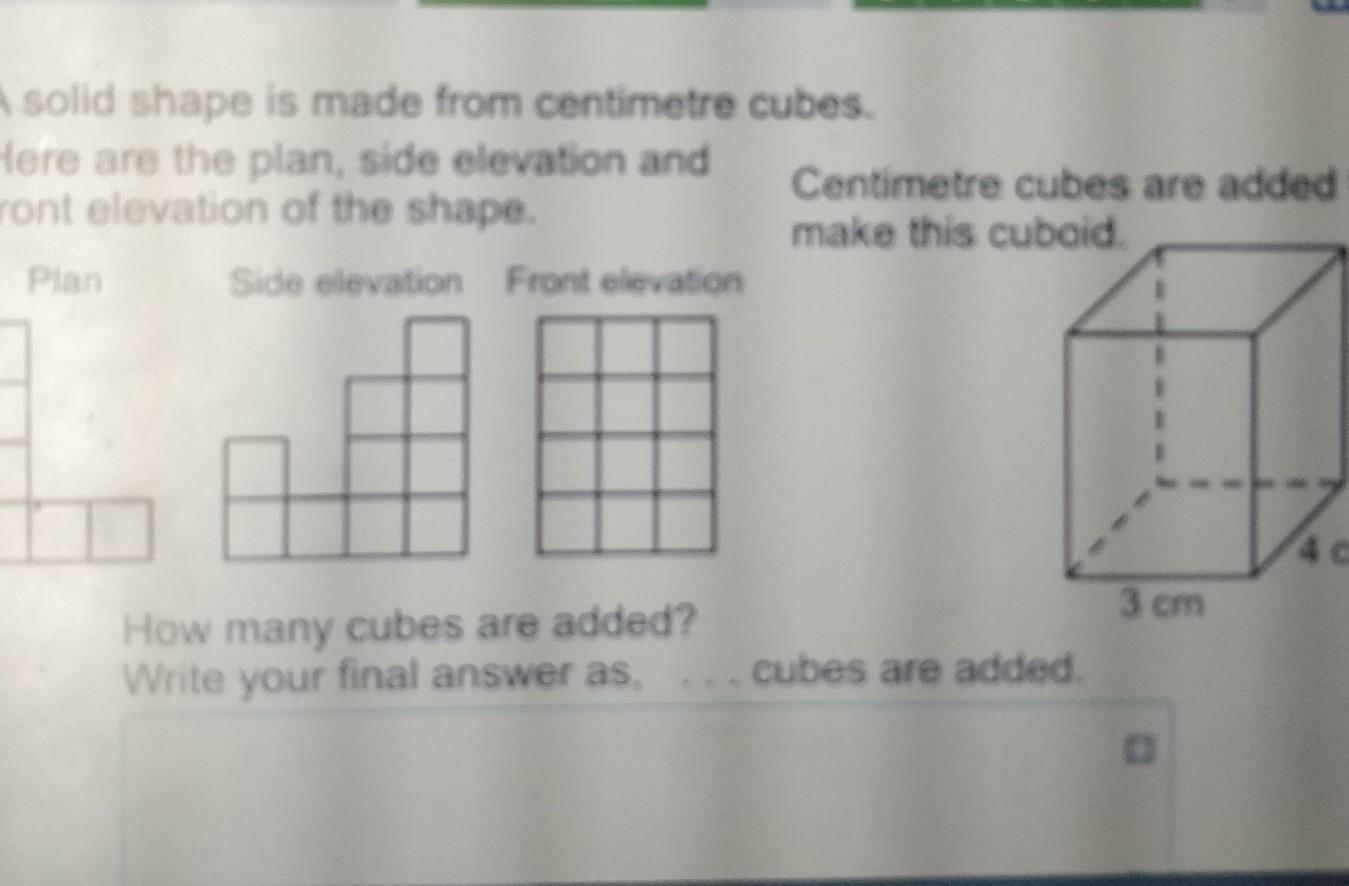
30 cubes are added
Step-by-step explanation:
The image of the solid shape is attached.
From the Plan, Side elevation and Front elevation, the number of cubes needed to make the shape is 18 blocks. From the front elevation, 12 blocks is needed (4 * 3 blocks) while from the side elevation 6 blocks are needed given a total of 18 blocks.
The number of blocks needed to make the cuboid = 4 * 4 * 3 = 48 cm cubes.
Therefore the number of cubes to be added = 48 cubes - 18 cubes = 30 cubes.
30 cubes are added