B, I took this test recently and got it right
Answer:
around 90 cm because that measure is equal to 180 you divide into 2 so the answer is 90
Answer:
C
Step-by-step explanation:
Hi there!
To the nearest penny, c = $85.94.
Total of payments = amount financed + c = $635.94.
Total of payments ÷ number of payments = monthly payment = $26.50
Your friend, ASIAX
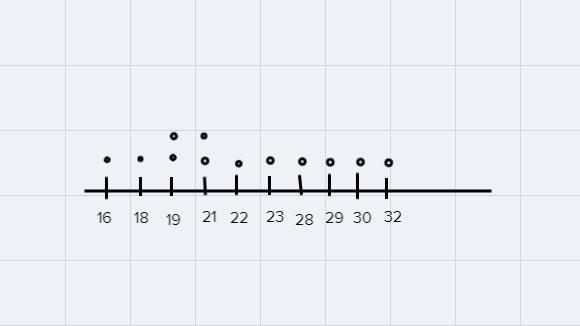
Recall that in statistics, the mode is the value that appears most frequently in a set of data. You may find it useful to represent the data in statistical graphs such as dot plots or bar charts. In this case, we will use the following chart
As we can see from the image, The most frequently used numbers are 19 and 21. We are dealing with a bimodal data set. The mode is given by 19 and 21.