Answer:
Five careers in the Arts, A/V Technology, and Communications cluster that would be interesting to me are choreographer, museum conservator, reporter, singer, and fashion designer. Of those careers, being a museum conservator, singer, or fashion designer sounds the most appealing to me. Out of all those choices, I think that being a fashion designer seems the most interesting and would allow me to use my creativity.
Fashion designers create patterns and construct sample garments for a target market. They use models to determine how the garments will fit and modify them as necessary to get the desired look. In order to excel in this position, I would need to be able to think creatively; establish working relationships with models, designers, and others in the industry; and organize my time in order to accomplish the necessary work and meet deadlines.
There are several schools that offer a degree in fashion design, such as Savannah College of Art and Design, Academy of Art University in San Francisco, Kent State University, and the University of Cincinnati. Several technical schools also focus on fashion design, such as the Fashion Institute of Design & Merchandising. I think I would choose to attend Parsons in New York, which has turned out many famous fashion designers, such as Marc Jacobs, Jenna Lyons, and Tom Ford.
Explanation:
plato answer
Answer:
see explaination
Explanation:
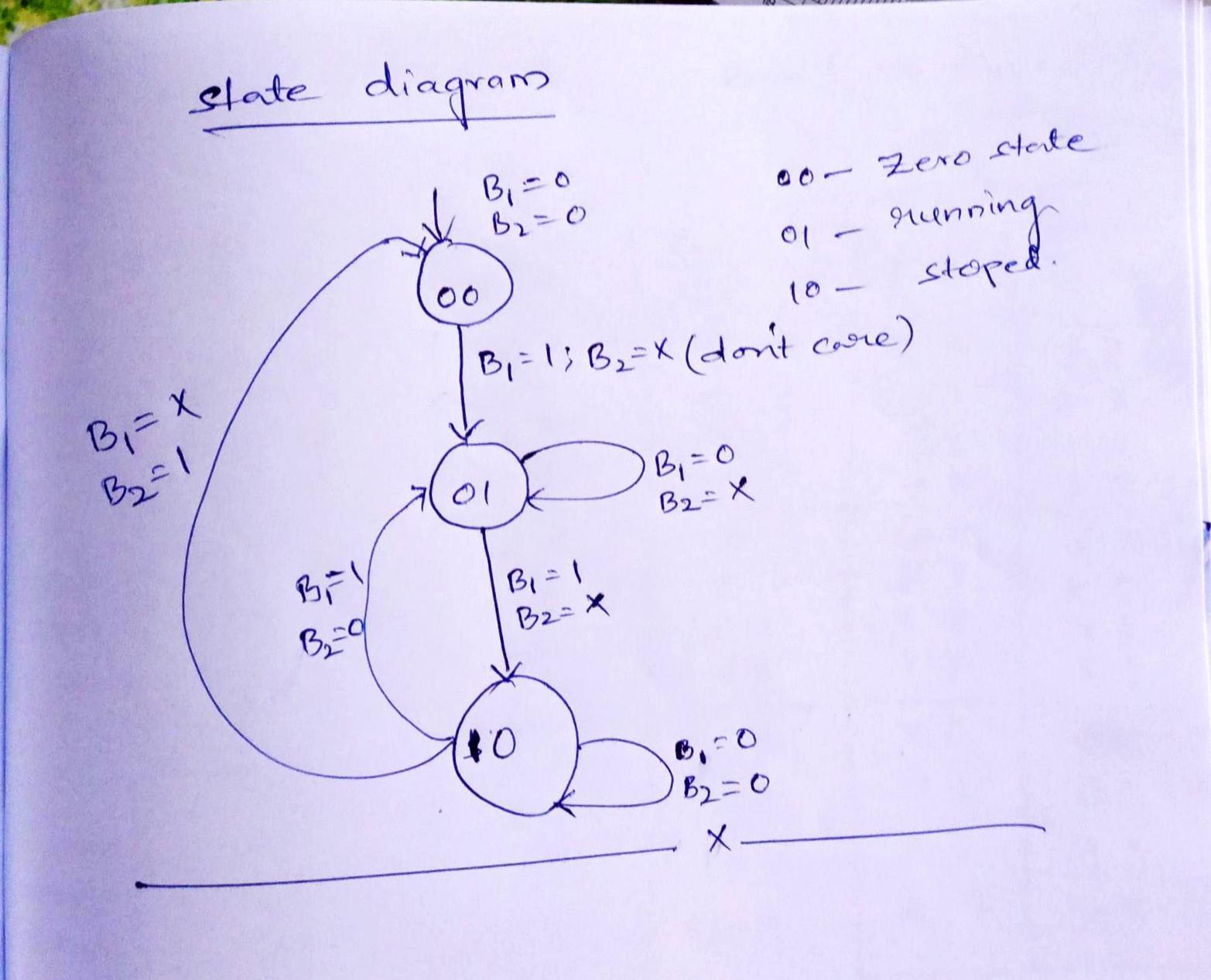
State Diagram based on given in the problem and state table, k-map for j and k, based j and k expressions we can draw the (FSM )controller using j and j flip flop.
see attachment for this.
Answer:
CTRL + Z
Explanation:
Privileged exec mode and global configuration are command line interface mode structures used in Cisco’s routers and switches. They are like security levels that administrators log into and perform configuration changes. Global configuration mode gives you more root access than the former and you can do a lot more in this mode. While in Global configuration mode, you can switch back to the Privileged exec mode by pressing the CTRL + Z keyboard combination keys.
Answer:
She should be aware several social media spectators are going to watch her content. She will get exposed on the Internet.
Explanation:
She should be aware several social media spectators are going to watch her content. She will get exposed on the Internet.
She should think before saying anything as one of his fans may complaint about her content to the police if she makes a joke about shooting up a place.
She has to be careful with his words as this may lead to termination from the job.