Invitamos cordialmente a leer el desarrollo del problema para mayor detalle sobre el análisis de la situación y la construcción del diagrama.
<h3>Cómo construir un diagrama a partir de un enunciado</h3>
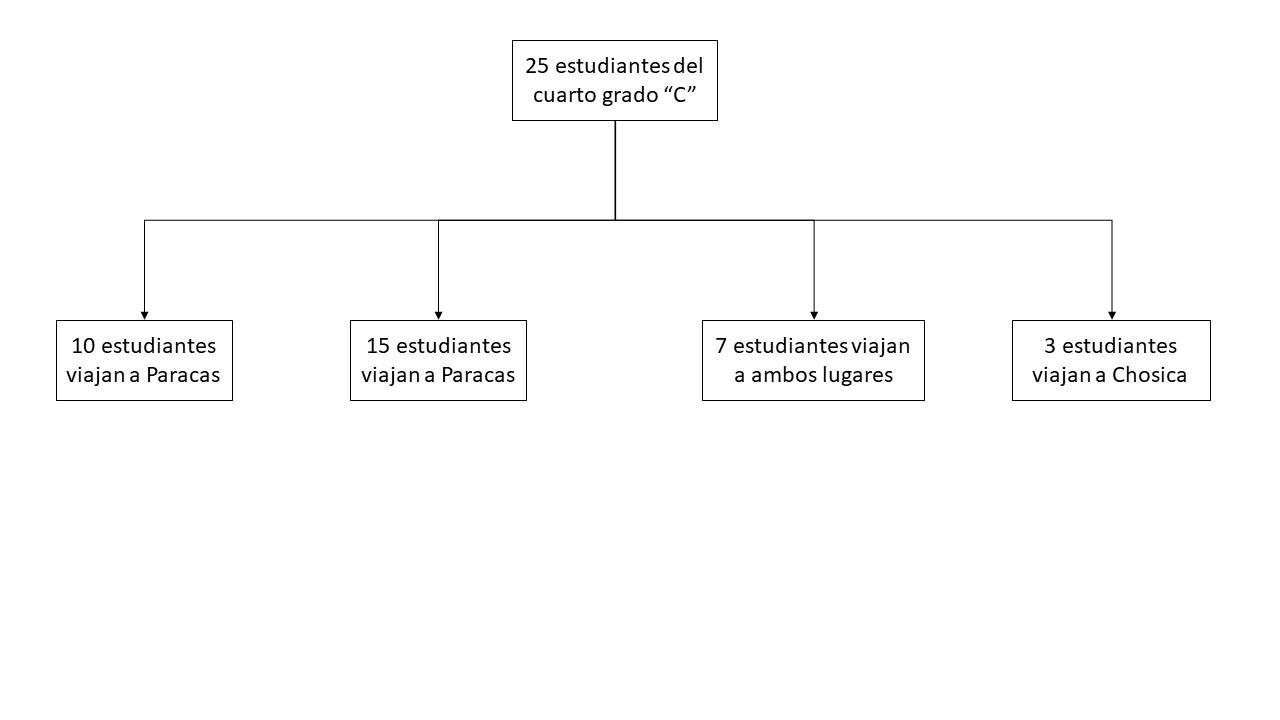
En esta pregunta debemos elaborar un diagrama de flujo, puesto que el enunciado muestra de manera evidente una clasificación de los viajeros según las ciudades de destino.
Nótese que se trata de un diagrama bastante simple, dado que no existe evidencia de jerarquización entre las ciudades mencionadas.
Tras una lectura cuidadosa del enunciado encontramos que de 25 estudiantes de cuarto grado "C" que decidieron irse de viaje, 10 viajaron a Paracas, 15 viajaron a Arequipa, 7 viajaron a los dos lugares citados y 3 viajaron a Chosica.
A continuación, presentamos el diagrama de flujo asociado a este caso en la imagen adjunta abajo.
Para aprender más sobre diagramas, invitamos cordialmente a ver esta pregunta verificada: brainly.com/question/10092453
Answer:
The vector that describes their hike from their starting position to their final destination is ![\vec r = 7\,\hat{i}+1\,\hat{j}\,\,\,[mi]](https://tex.z-dn.net/?f=%5Cvec%20r%20%3D%207%5C%2C%5Chat%7Bi%7D%2B1%5C%2C%5Chat%7Bj%7D%5C%2C%5C%2C%5C%2C%5Bmi%5D) .
.
Step-by-step explanation:
In this problem we assume that orthogonal axes coincide with the north and east. We proceed to translate each sentence from statement into vectorial equations:
(i) <em>A group of hikers walks 3 miles east and then 1 mile north:</em>
![\vec r_{A} = 3\,\hat{i}+1\,\hat{j}\,\,\,[mi]](https://tex.z-dn.net/?f=%5Cvec%20r_%7BA%7D%20%3D%203%5C%2C%5Chat%7Bi%7D%2B1%5C%2C%5Chat%7Bj%7D%5C%2C%5C%2C%5C%2C%5Bmi%5D)
(ii) <em>After taking a break, they then hike 4 miles east to their final destination:</em>
![\vec r_{B} = 4\,\hat{i}\,\,\,[mi]](https://tex.z-dn.net/?f=%5Cvec%20r_%7BB%7D%20%3D%204%5C%2C%5Chat%7Bi%7D%5C%2C%5C%2C%5C%2C%5Bmi%5D)
The vector that describes their hike from their starting position to their final destination is the sum of the vectors deducted above. That is:
 (1)
(1)
![\vec r = (3\,\hat{i}+1\,\hat{j})+4\,\hat{i}\,\,\,[mi]](https://tex.z-dn.net/?f=%5Cvec%20r%20%3D%20%283%5C%2C%5Chat%7Bi%7D%2B1%5C%2C%5Chat%7Bj%7D%29%2B4%5C%2C%5Chat%7Bi%7D%5C%2C%5C%2C%5C%2C%5Bmi%5D)
The vector that describes their hike from their starting position to their final destination is .
Answer:
60%
Step-by-step explanation:
Total number of pies = 40
Number of coconut pies = 24
Percentage of coconut pies :
(Number of coconut pies / total number of pies) * 100%
(24 / 40) * 100%
0.6 * 100%
= 60%
60% of pies are coconut pies
Commutative Property allows 5=b to be written as b=5!
I hope this helped! Mark me Brainliest! :) -Raven❤️
Answer:
612
Step-by-step explanation:
The lateral surface area does not include the bases.
The bases are the triangles
We will add up the areas of the three rectangles
We have the two rectangles on the sides which are 17 by 13 and the rectangle on the bottom which is 17 by 10
17* 13 + 17*13 + 17*10 =612