Answer:
a) 
b) 
c) 
And using a calculator, excel or the normal standard table we have that:

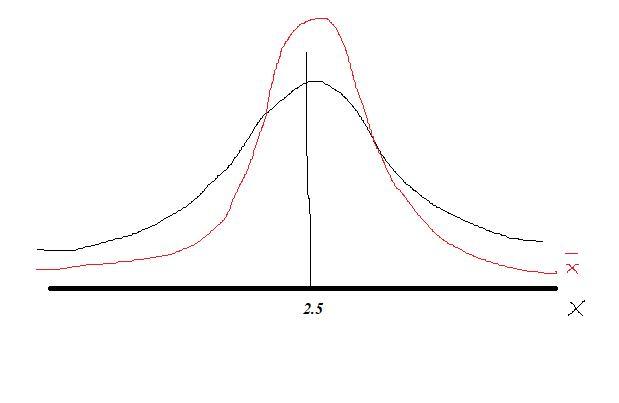
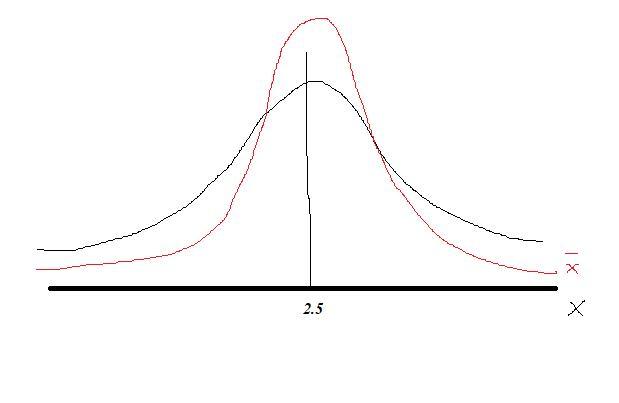
d) Figure attached
e) If we don't know the distribution then we can't ensure that the sample mean would be distributed like this:

And we can't estimate the probabilities on a easy way.
Step-by-step explanation:
Previous concepts
Normal distribution, is a "probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean".
The Z-score is "a numerical measurement used in statistics of a value's relationship to the mean (average) of a group of values, measured in terms of standard deviations from the mean".
Part a
Let X the random variable that represent the weights of a population, and for this case we know the distribution for X is given by:

Where  and
and 
We are interested on this probability

And the best way to solve this problem is using the normal standard distribution and the z score given by:

If we apply this formula to our probability we got this:
And we can find this probability on this way:

Part b
Since the distribution for X is normal then the distribution for the sample mean is:
Part c
And using a calculator, excel or the normal standard table we have that:
Part d
See the figure attached the deviation for the sample mean is lower for this reason we have the pattern in the graph attached.
Part e
If we don't know the distribution then we can't ensure that the sample mean would be distributed like this:
And we can't estimate the probabilities on a easy way.