1,000,000 days x 24 hours = 24,000,000 hours
<span>The answer is 29√5.
</span>
Since 11√45 and 4√5 do not share a common radical, you cannot subtract them. By looking at the equation, you can see that 11√45 is not fully simplified yet by the 45 within the square root.
Breaking it up into squares, you can find that 3 x 3 x 5 = 45, which can be translated into 3<span>² x 5</span>. Since the 3 is a square component in the 45, you can now extract it. Extract the 3 by dividing it from the 45 within the square root and multiplying it into the 11.
Your result is a 33√5, which shares a common radical with 4√5. You can now subtract 33√5 and 4√5, which is 29√5.
Side note: I noticed you got the answer wrong because you chose 7√40. I presume it's because you subtracted the components individually. I suggest that you look up lessons about simplifying radicals, along with adding and subtracting them. Hope this helps!
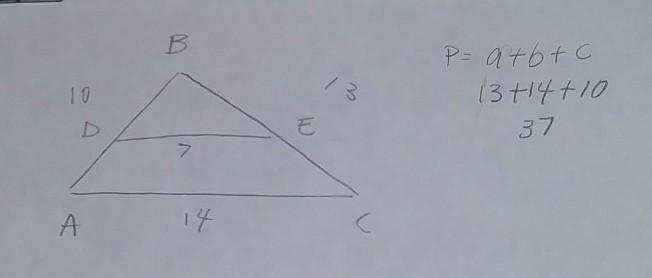
Answer:
The perimeter is 37
Step-by-step explanation:
there you go
This is the concept of indices. To re-write the question as instructed we proceed as follows:
b^-6×b^11
according to the rules of indices, when we multiply the number which have the same base, we add their powers. In our case this will be:
b^-6×b^11
adding their powers we get:
b^(-6+11)
=b^5
the answer will therefore be b^5
I do know the bottom one is 2.8
Top is 1.6
I don’t know the middle one