9514 1404 393
Answer:
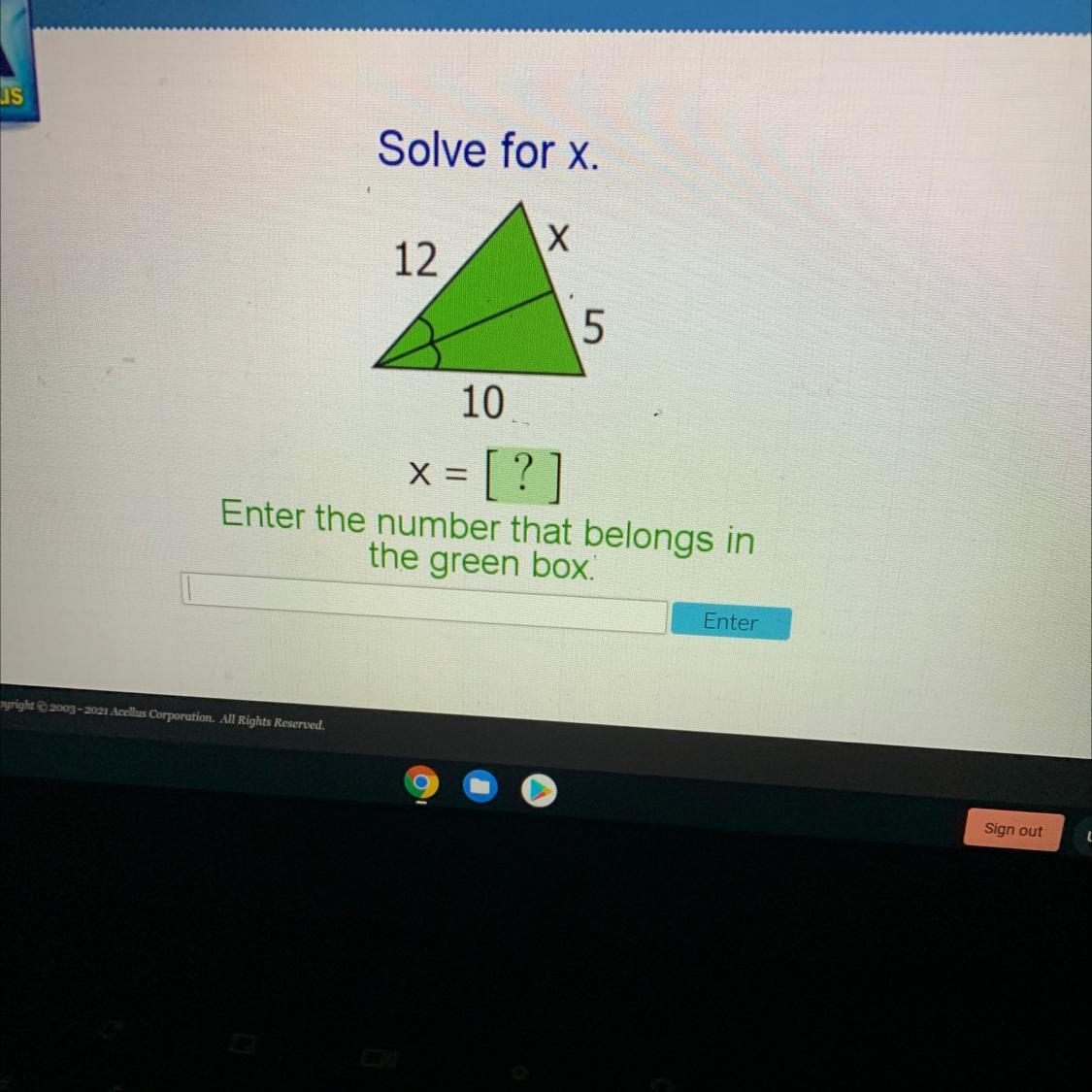
x = 6
Step-by-step explanation:
The two angles are marked as being equal, so the line down the middle of the triangle is an angle bisector. An angle bisector divides the sides of the triangle proportionally, so you can write the proportion ...
x/12 = 5/10
x = 12(5/10) . . . . multiply by 12
commutative property of multiplication
3 * 5 means 5 + 5 + 5 which equals 15.
5 * 3 means 3 + 3 + 3 + 3 + 3 which equals 15.
D.
3
$7.44
$4.96/ 2= 2.48
$2.48 X 3 = 7.44