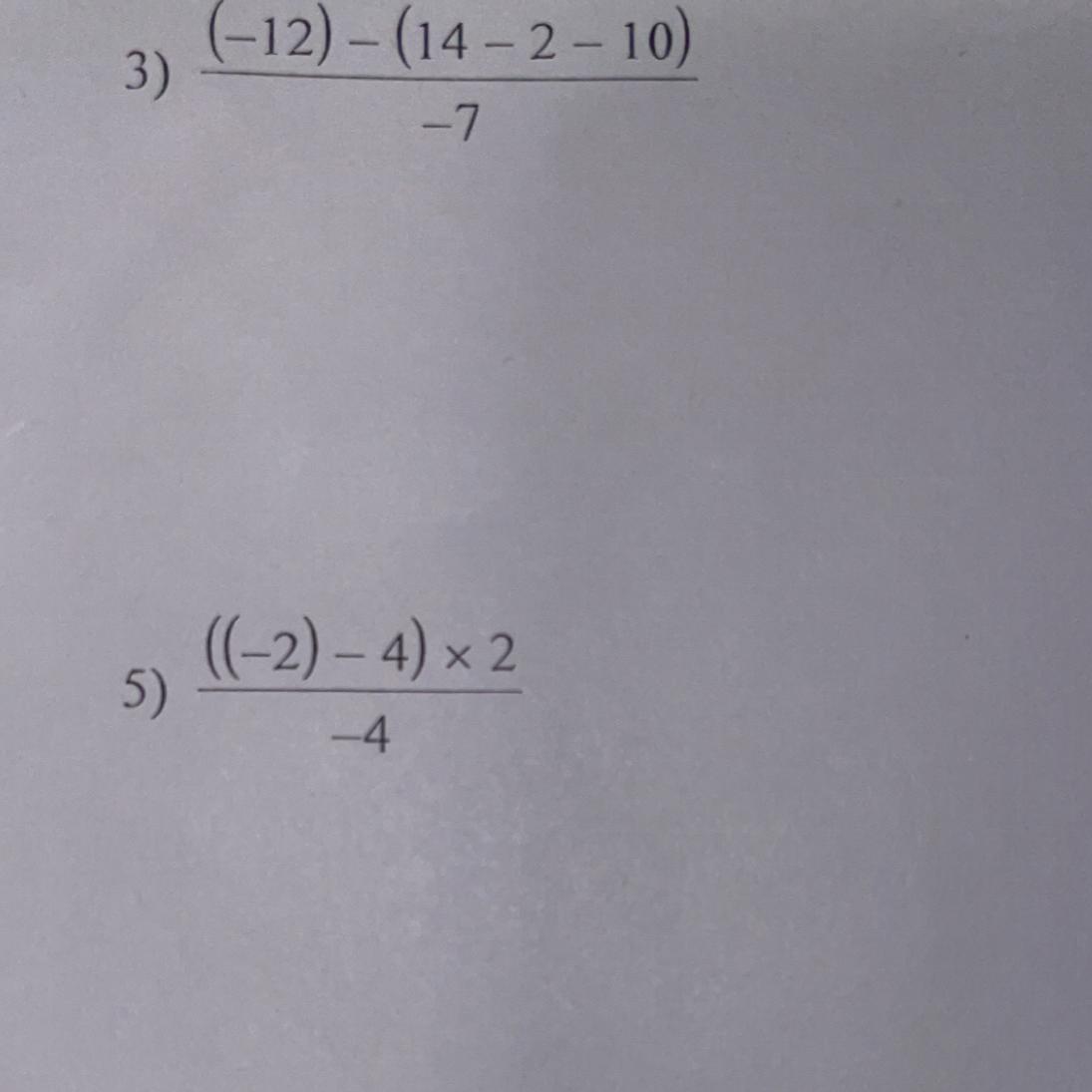Answer:
its the last one ;)
Step-by-step explanation:
Answer:
So, y = 2x + 7;
Then, 2x = 4( 2x + 7 ) - 16;
2x = 8x + 28 - 16;
2x = 8x + 12;
- 6x = 12;
x = - 2;
Then, y = 2· (-2) + 7;
y = - 4 + 7;
y = 3.
Step-by-step explanation:
Yes, because 54 divided by 13 equals 4, 52/13=4
48×56=2,688 that will be the correct answer
Implicit or Doubtful memory of actual events that was stored encrypted, but was not retrieved for a long time until subsequent events suddenly brought it back to consciousness. The establishing, stabilizing like processes include in this memory.
Implicit Memory is a type of long-term memory and it is also known as unconscious memory or automatic memory. Implicit memory draws on past experiences to remember things without thinking. The power of tacit memory is made possible by past experiences, regardless of how long ago those experiences were.
Second stage of long-term memory formation.
Implicit memory, a subset of procedural memory, allows you to perform many everyday physical activities, such as walking and cycling, without having to think about it. Most of the implicit storage is procedural in nature.
For example:
- typing on a keyboard
- brushing your teeth. Riding a bicycle
- Most people find it easy to ride a bike, even after years of not riding.
To learn more about Implicit Memory, refer:
brainly.com/question/15033888
#SPJ4