Answer:
Explanation:
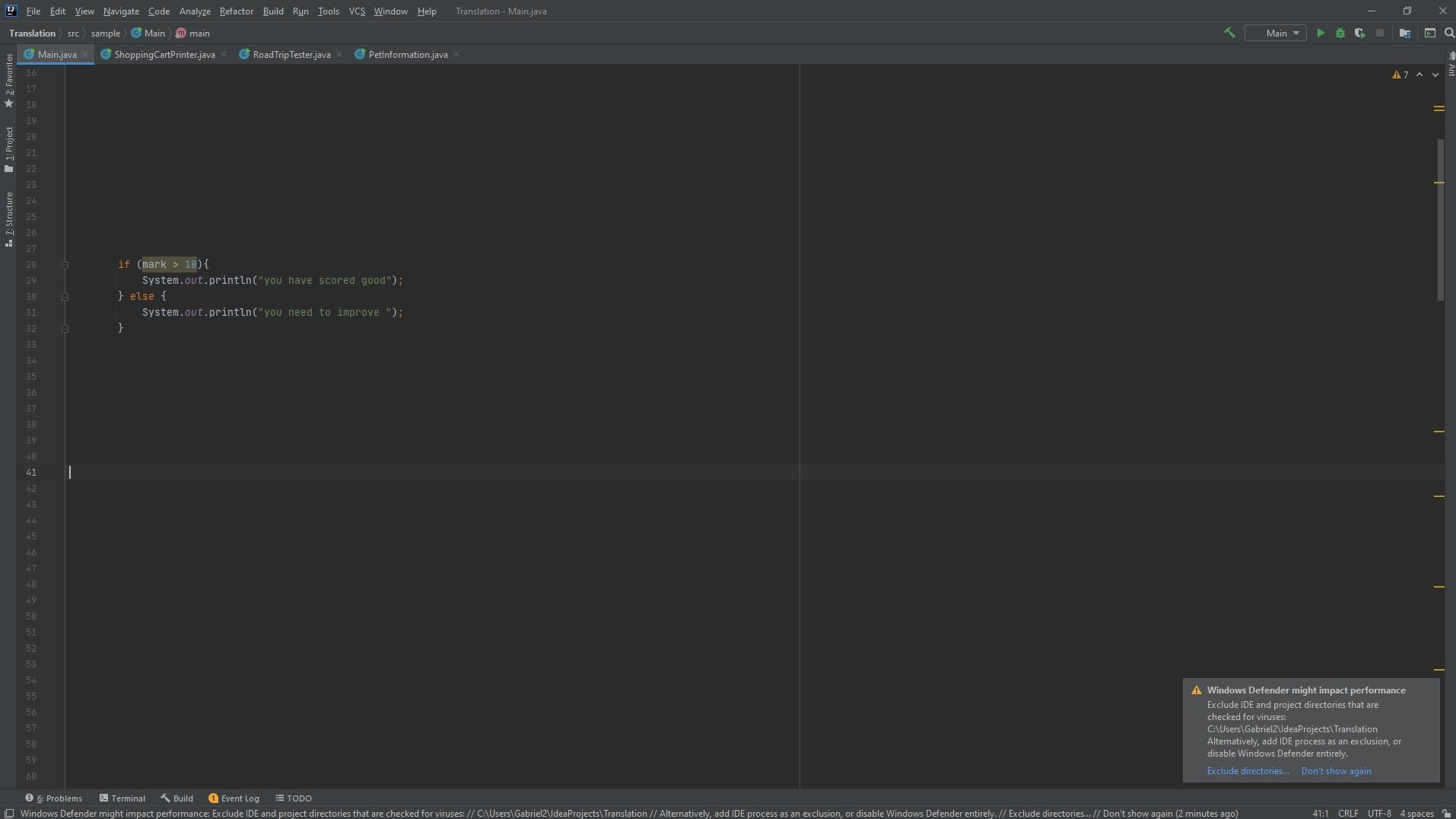
The following code is written in Java. The if() function is actually called an if statement. The following code can be copied and pasted where you need as long as it is within the scope of the mark variable in order to call it and compare it to 10
if (mark > 10){
System.out.println("you have scored good");
} else {
System.out.println("you need to improve ");
}
By default, the windows desktop display the following icons/programs
1. Your Recycle Bin
2. My Computer
3. The Internet Explorer
4. The default Windows Background
5. Your windows menu
6. My Documents
7. Your task bar
8. Time (located at bottom right)
The most appropriate answer is C !! software os used for using hardware !!