Answer:
Filled below
Explanation:
#v.e means number of valence electrons.
Also, the column total v.e is gotten by adding the v.e of the metal to the v.e of the non metal based on the chemical formula of both of the 2 elements combined.
K: Cl: 5; KCl; 1 + 5 = 6
Be: S: 6; BeS; 2 + 6 = 8
Na: F: 7; NaF; 1 + 7 = 8
Mg: Se: MgSe; 2 + 6 = 8
Al; N; AlN; 1 + 5 = 6
Be; F; BeF2; 2 + 2(7) = 16
Mg; N; Mg3N2; 3(2) + 2(7) = 20
We can use distillation to separate liquid to liquid
Answer:
It keeps us alive, helps us grow plants, helps plants thrive, gives us food, helps keep our animals and crops healthy, cleans us, and so much more
Explanation:
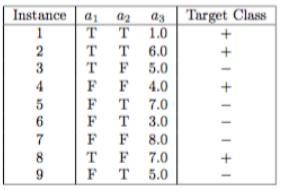
The data set is missing in the question. The data set is given in the attachment.
Solution :
a). In the table, there are four positive examples and give number of negative examples.
Therefore,
 and
and

The entropy of the training examples is given by :

= 0.9911
b). For the attribute all the associating increments and the probability are :
 + -
+ -
T 3 1
F 1 4
Th entropy for is given by :
![$\frac{4}{9}[ -\frac{3}{4}\log\left(\frac{3}{4}\right)-\frac{1}{4}\log\left(\frac{1}{4}\right)]+\frac{5}{9}[ -\frac{1}{5}\log\left(\frac{1}{5}\right)-\frac{4}{5}\log\left(\frac{4}{5}\right)]$](https://tex.z-dn.net/?f=%24%5Cfrac%7B4%7D%7B9%7D%5B%20-%5Cfrac%7B3%7D%7B4%7D%5Clog%5Cleft%28%5Cfrac%7B3%7D%7B4%7D%5Cright%29-%5Cfrac%7B1%7D%7B4%7D%5Clog%5Cleft%28%5Cfrac%7B1%7D%7B4%7D%5Cright%29%5D%2B%5Cfrac%7B5%7D%7B9%7D%5B%20-%5Cfrac%7B1%7D%7B5%7D%5Clog%5Cleft%28%5Cfrac%7B1%7D%7B5%7D%5Cright%29-%5Cfrac%7B4%7D%7B5%7D%5Clog%5Cleft%28%5Cfrac%7B4%7D%7B5%7D%5Cright%29%5D%24)
= 0.7616
Therefore, the information gain for is
0.9911 - 0.7616 = 0.2294
Similarly for the attribute  the associating counts and the probabilities are :
the associating counts and the probabilities are :
+ -
T 2 3
F 2 2
Th entropy for is given by :
![$\frac{5}{9}[ -\frac{2}{5}\log\left(\frac{2}{5}\right)-\frac{3}{5}\log\left(\frac{3}{5}\right)]+\frac{4}{9}[ -\frac{2}{4}\log\left(\frac{2}{4}\right)-\frac{2}{4}\log\left(\frac{2}{4}\right)]$](https://tex.z-dn.net/?f=%24%5Cfrac%7B5%7D%7B9%7D%5B%20-%5Cfrac%7B2%7D%7B5%7D%5Clog%5Cleft%28%5Cfrac%7B2%7D%7B5%7D%5Cright%29-%5Cfrac%7B3%7D%7B5%7D%5Clog%5Cleft%28%5Cfrac%7B3%7D%7B5%7D%5Cright%29%5D%2B%5Cfrac%7B4%7D%7B9%7D%5B%20-%5Cfrac%7B2%7D%7B4%7D%5Clog%5Cleft%28%5Cfrac%7B2%7D%7B4%7D%5Cright%29-%5Cfrac%7B2%7D%7B4%7D%5Clog%5Cleft%28%5Cfrac%7B2%7D%7B4%7D%5Cright%29%5D%24)
= 0.9839
Therefore, the information gain for is
0.9911 - 0.9839 = 0.0072
 Class label split point entropy Info gain
Class label split point entropy Info gain
1.0 + 2.0 0.8484 0.1427
3.0 - 3.5 0.9885 0.0026
4.0 + 4.5 0.9183 0.0728
5.0 -
5.0 - 5.5 0.9839 0.0072
6.0 + 6.5 0.9728 0.0183
7.0 +
7.0 - 7.5 0.8889 0.1022
The best split for observed at split point which is equal to 2.
c). From the table mention in part (b) of the information gain, we can say that produces the best split.