Answer:
Explanation:
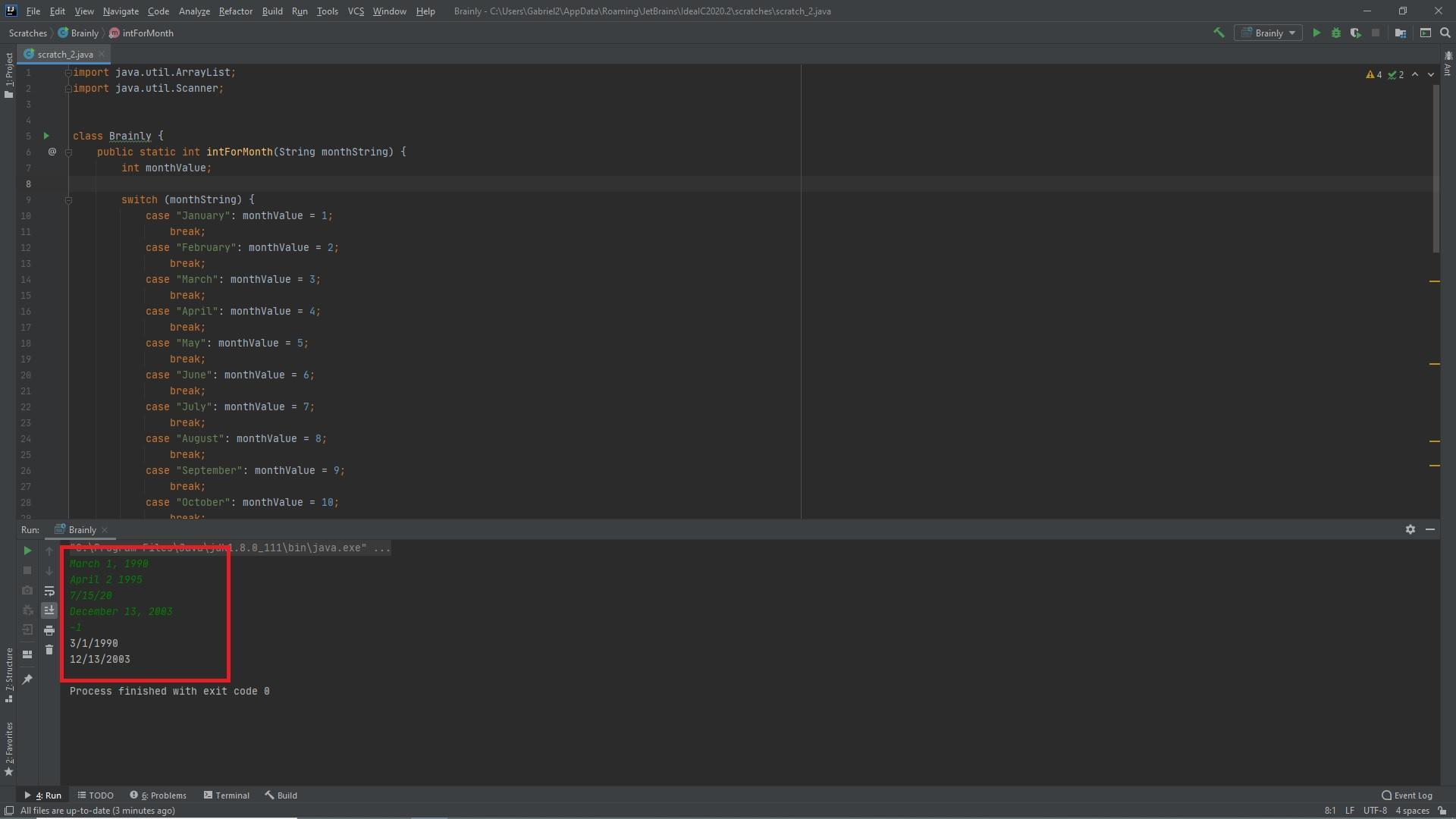
The following code was written in Java it creates a switch statement for all the month values in order to turn them from Strings into integer values. Then it reads every line of input places them into an array of dates if they are the correct input format, and loops through the array changing every date into the correct output format.Ouput can be seen in the attached picture below.
import java.util.ArrayList;
import java.util.Scanner;
class Brainly {
public static int intForMonth(String monthString) {
int monthValue;
switch (monthString) {
case "January": monthValue = 1;
break;
case "February": monthValue = 2;
break;
case "March": monthValue = 3;
break;
case "April": monthValue = 4;
break;
case "May": monthValue = 5;
break;
case "June": monthValue = 6;
break;
case "July": monthValue = 7;
break;
case "August": monthValue = 8;
break;
case "September": monthValue = 9;
break;
case "October": monthValue = 10;
break;
case "November": monthValue = 11;
break;
case "December": monthValue = 12;
break;
default: monthValue = 00;
}
return monthValue;
}
public static void main(String[] args) {
Scanner scnr = new Scanner(System.in);
ArrayList<String> dates = new ArrayList<>();
String date;
String month;
String day;
String year;
int i = 0;
while (true) {
date = scnr.nextLine();
if (date.equals("-1")) {
break;
}
dates.add(date);
}
for (i = 0; i < dates.size(); i++) {
try {
month = dates.get(i).substring(0, dates.get(i).indexOf(" "));
day = dates.get(i).substring(dates.get(i).indexOf(" ") + 1, dates.get(i).indexOf(","));
year = dates.get(i).substring(dates.get(i).indexOf(",") + 2, dates.get(i).length());
System.out.println(intForMonth(month) + "/" + day + "/" + year);
} catch (Exception e) {}
}
}
}