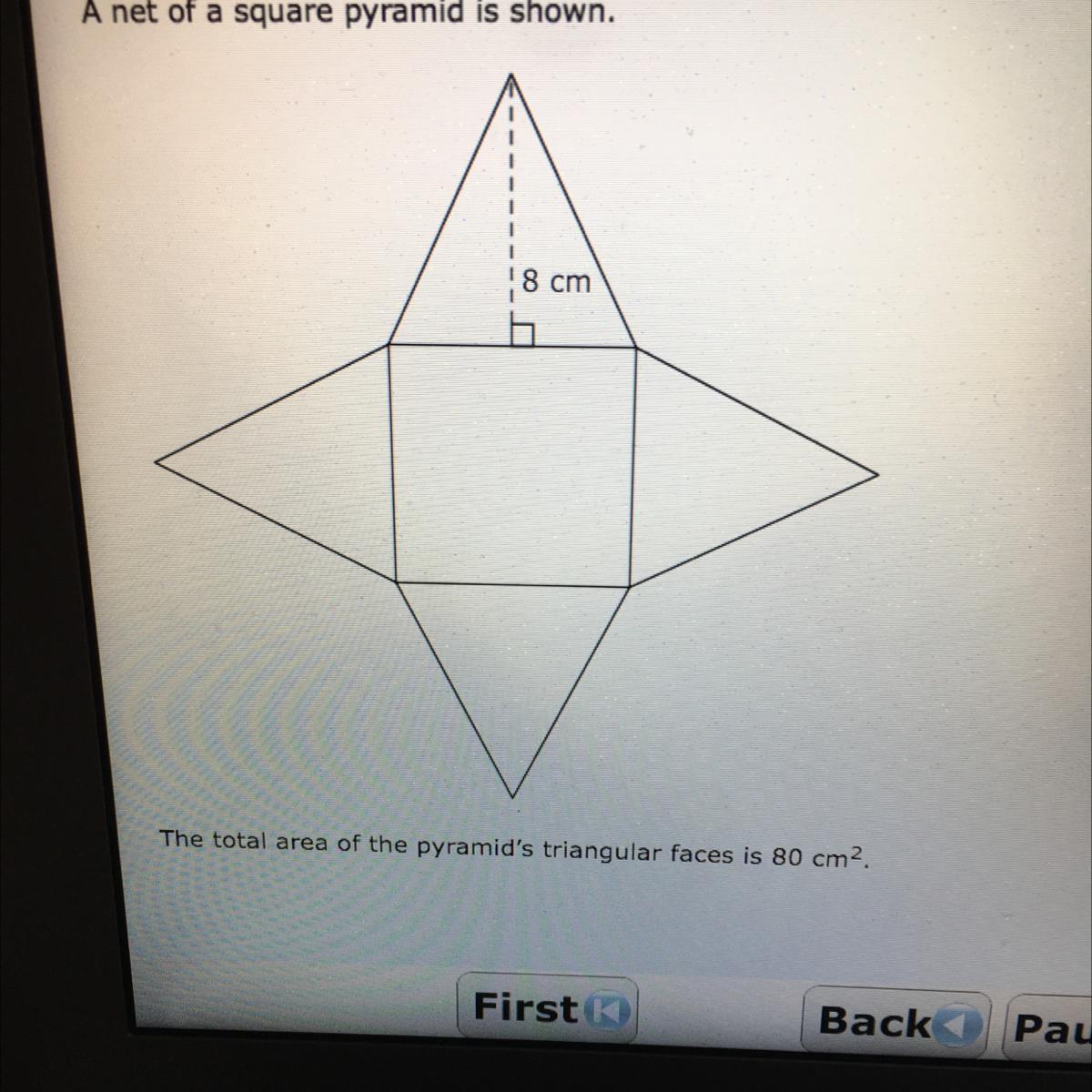
What is the area of the pyramid square base
1 answer:
Answer:
25 cm^2
Step-by-step explanation:
the area of 1 triangle is 20, so the missing length of the triangle is 5. 5x5=25
You might be interested in
Answer:
8
Step-by-step explanation:
4(x-3)=20 8-3=5 4(5)=20
Answer:
ones
Step-by-step explanation:
Answer:
-3
Step-by-step explanation: or if it -11/3 - 12/3 then its -23/3
Answer:
A
Step-by-step explanation:
y component=17 sin 81≈16.7907≈16.8
8r and -6r are like terms. What is 8r-6r?