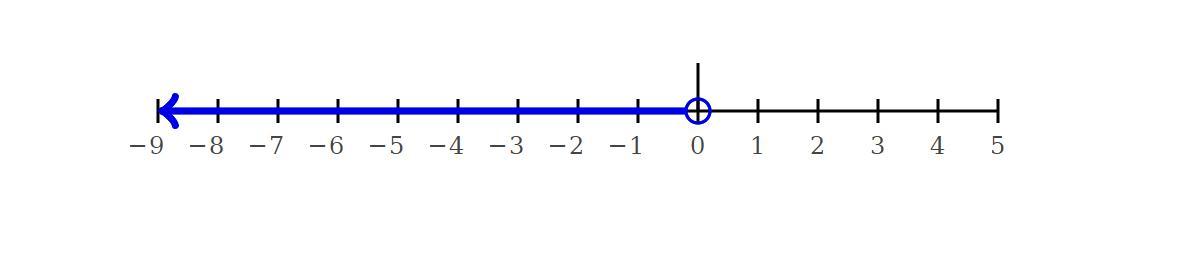
Answer:
i think you meant -r > 0 so here is the graph for that:
Step-by-step explanation:
just ask!
Sure jejshehhdjsjshdhdhdjsjdjdjd
X = 5
Step-by-step explanation:
78 = 12x+18
-18 -18
60 = 12x
5 = x
So yeah the correct answer is y. I hope this is what u needed.
Answer:
The answer is D.
Step-by-step explanation:
It's D because a expression is numbers grouped together not just 1 number. Hope it helps and have a blessed day.