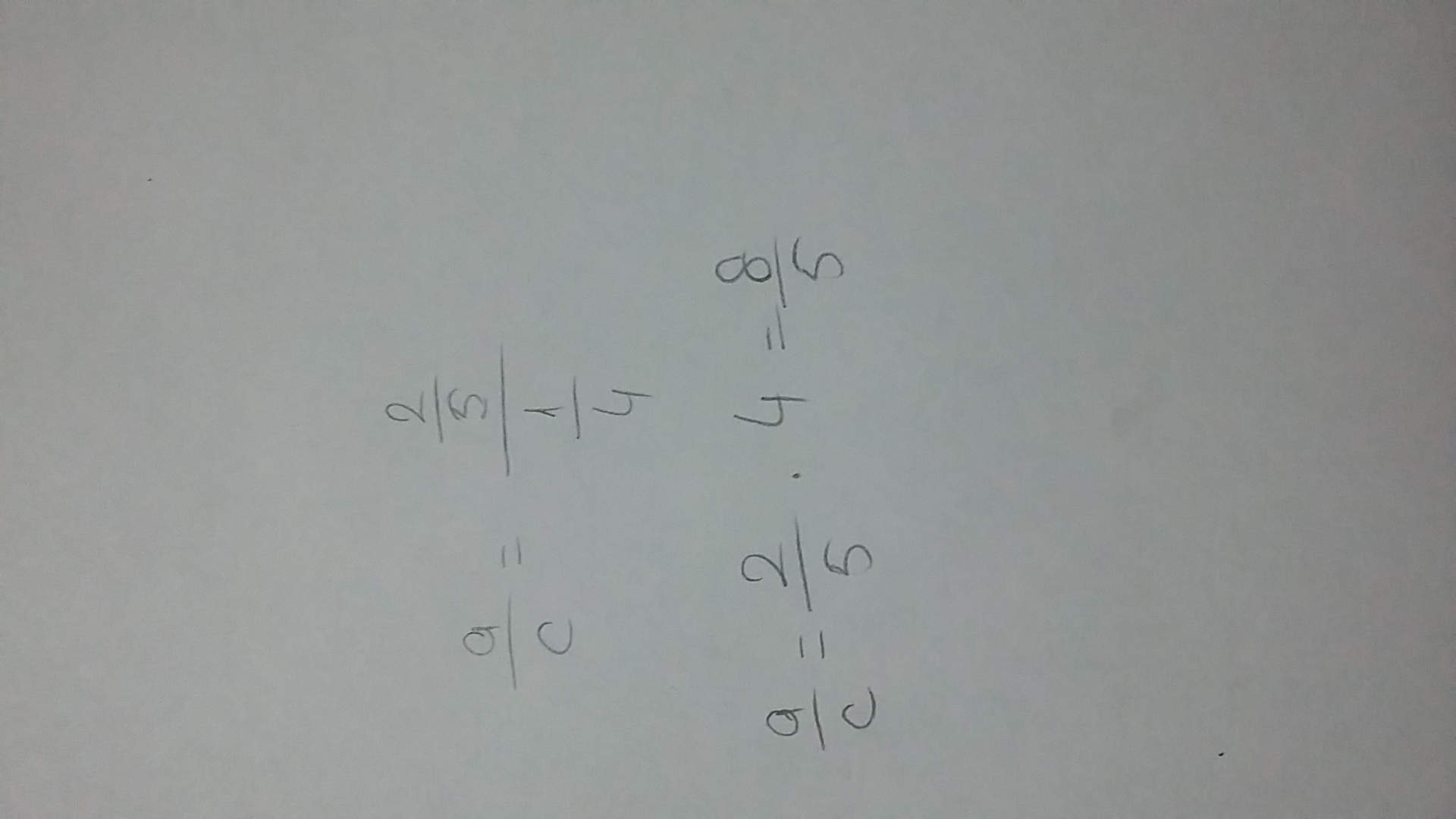Nose rkrbtje de donde salió la luz de
It will take 20 days to make 20 craft pieces.
If she can make 5 in 5 days, then it will take her 20 days to make 20 craft peices
Angle 6 and Angle 7 are each 90° since they’re on a straight line and are both equal.
180-90= 90
*you subtract from 180 because that’s how many degrees are in a straight line*
Angle 7 and Angle 1 are alternate exterior angles so that makes them congruent by definition.
Answer:
b = 74
Step-by-step explanation:
The exterior angle is equal to the sum of the opposite interior angles in a triangle
b-44 + b+18 = b+48
2b-26 = b+48
Subtract b from each side
2b-b-26 =b+48-b
b-26 = 48
Add 26 to each side
b-26+26 = 48+26
b =74