Answer:
a) Planning chart:
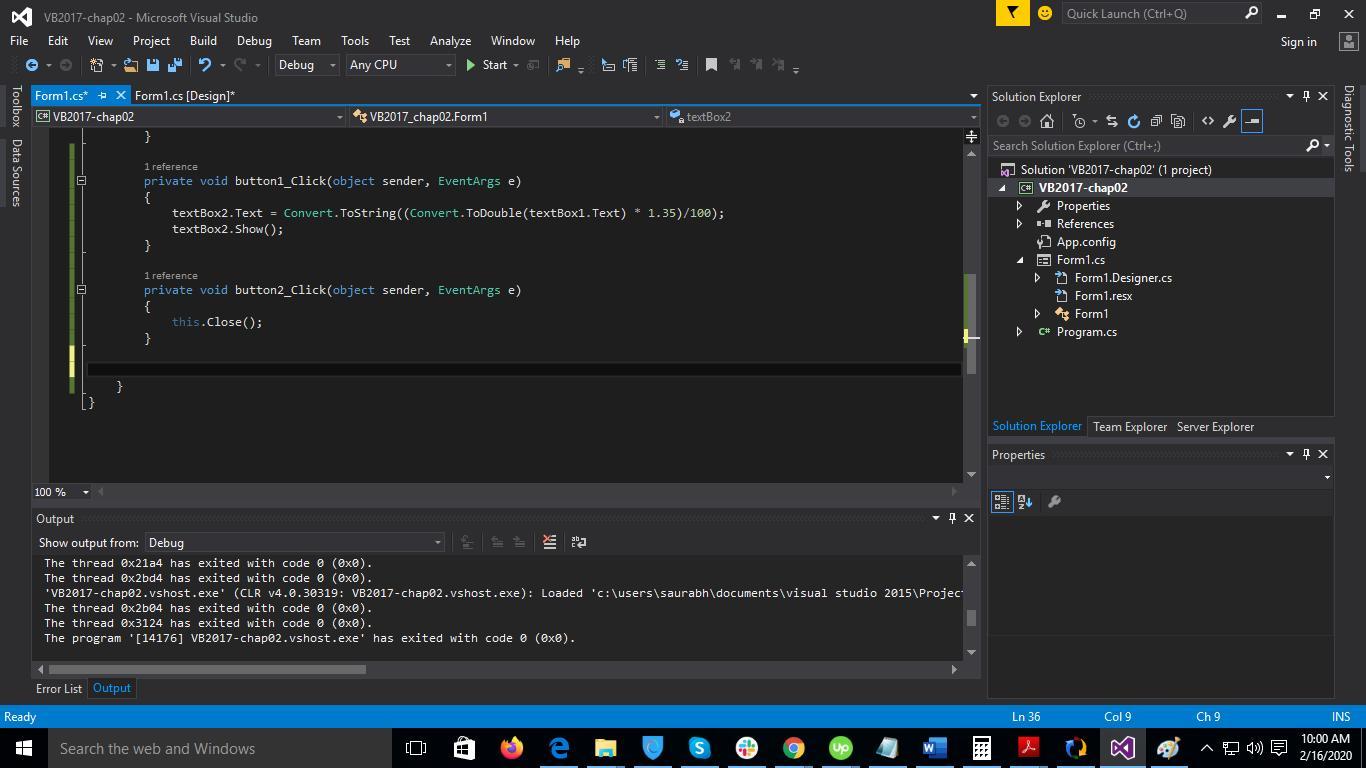
Create the form, and add two buttons, calculate and exit, and add two labels and two textboxes, as shown in the second image. Now code the buttons as shown in the image file, and debug. The required program is ready.
b) The design is as shown in the second image,
c) And the code for the windows form is also ready. Steps in brief. Open visual studio, Go to file menu and hit on New. Now choose Windows form from project type, and give the project name VB2017/chap02. Now code as explained in A, and as explained in images.
D) We just need to follow the plan to build the interface.
E) The code of exit button. Double click exit button to enter code-behind, and add this.Close(); And that's it, we have the project ready.
Explanation:
Please check the answer section.
And If you want Rounded off value, then you need to all below code in calc_click method. Double click on calc, and code behind will appear. Add the below code over there:
double tax = Convert.ToDouble((textBox1.Text)) * 5/100;
double Roundedtax = Math.Round(tax, 2);
textBox2.Text = Convert.ToString(Roundedtax);
textBox2.Show();
textBox3.Text = Convert.ToString(Convert.ToDouble(textBox1.Text) + Convert.ToDouble(textBox2.Text));
textBox3.Show();
For dollar sign, add a label after each textbox, and change its text to $s.