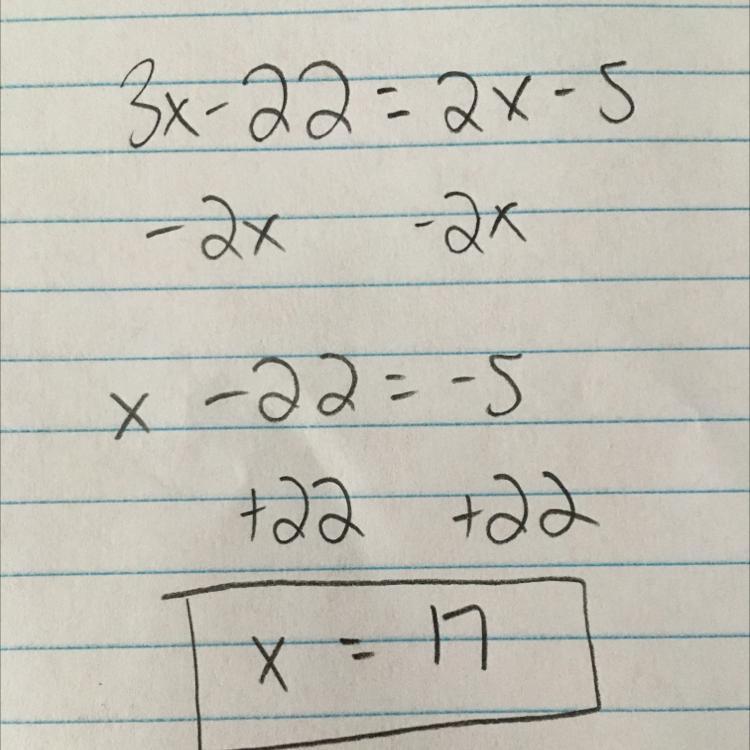The answer is x = 17, hope this helps :)
Option A: 1,1,1,1 is the right answer
Step-by-step explanation:
In finding the function iterates we start with the initial value and put the initial value into the function and then the output of previous iterate is used as input for next iterate
Given

<u>First iterate: </u>
Putting x=-1 in the function

<u>Second iterate:</u>
Putting x=1

<u>Third iterate:</u>
Putting x=1
<u>Fourth iterate:</u>
Putting x=1
First four iterates of given function with initial value -1 are: 1,1,1,1
Hence,
Option A: 1,1,1,1 is the right answer
Keywords: Functions, iterates
Learn more about function iteration at:
#LearnwithBrainly
On the number line, 3 and 11 are the numbers that are a distance of 4 units from 7..
On there are two types of numbers one is a positive and the other is a negative number. These two are separated by the number zero which is known as the origin. Positive numbers are on the right side of the origin and negative numbers are on the left side of the origin on the number line.
We have been asked the numbers which are a distance of 4 units from 7 on the number line.
For that, we will first add 4 to the number 7, that is,
4 + 7 = 11
Thus, number 11 is a distance of 4 units from 7 on the number line if we move to the right side from 7.
Now we will subtract 4 from the 7 we will get,
7-4 = 3
Thus, Number 3 is a distance of 4 units from 7 on the number line if we move to the left side from 7.
Hence 3 and 11 are the numbers that are a distance of 4 units from 7 on the number line.
Learn more about the number line here: brainly.com/question/77754
#SPJ9
Answer:
We also know that when you have the same numerator and denominator in a fraction, it always equals 1. For example: So as long as we multiply or divide both the top and the bottom of a fraction by the same number, it's just the same as multiplying or dividing by 1 and we won't change the value of the fraction.
Step-by-step explanation:
Answer:
By 2035 the town's population should be 20,532.