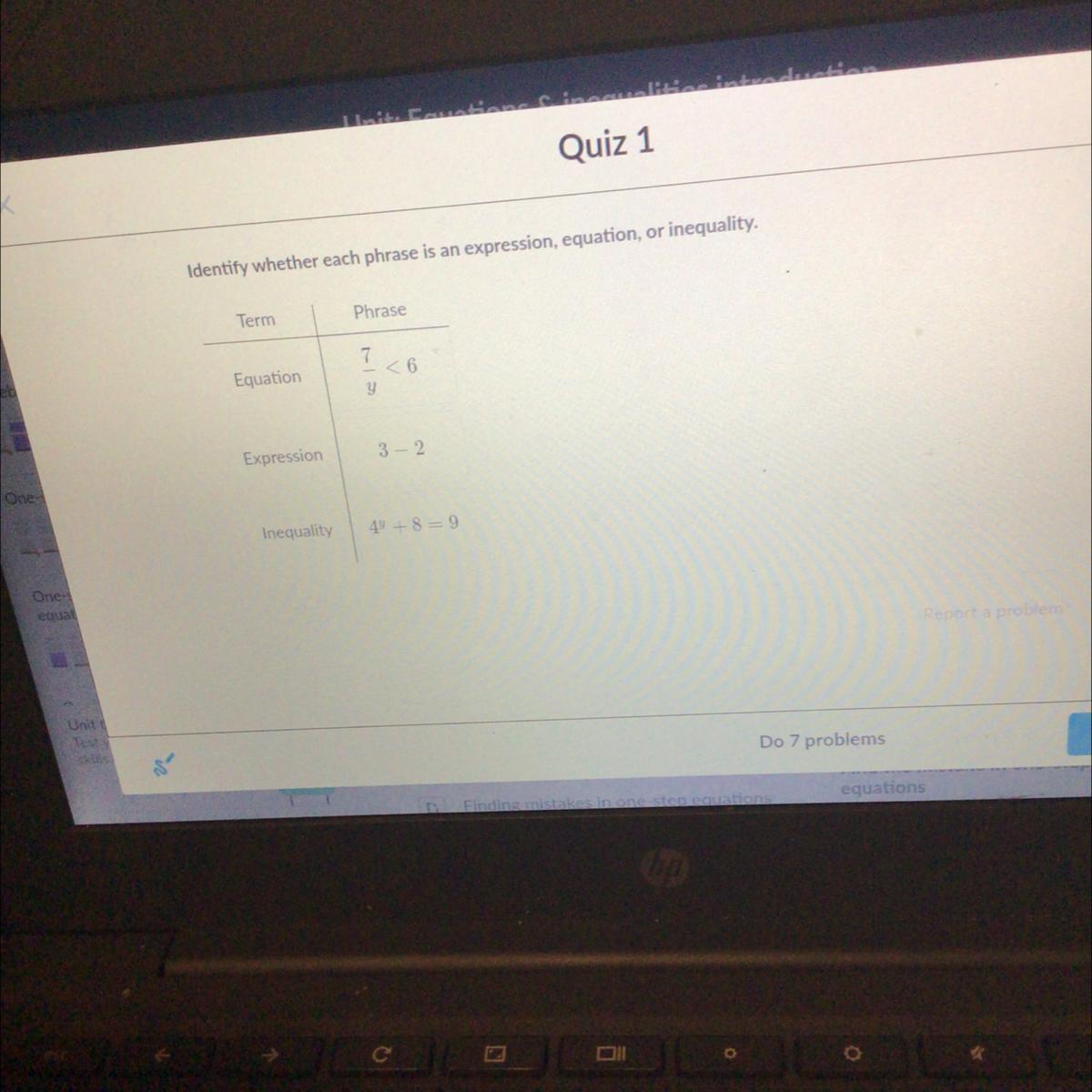
Answer:
[see below]
Step-by-step explanation:
An equation is a mathematical statement that states that two expressions are equal. Equations have an equal sign.
An inequality is a mathematical statement that states that two expressions are greater than, less than, greater than or equal to, or less than or equal to.
An expression is a combination of mathematical symbols that show the value of something. It does not have any inequality sign nor an equal sign.
 is an inequality. It has a less than sign.
is an inequality. It has a less than sign.
3 - 2 is an expression. It does not have any inequality sign nor an equal sign.
 is an equation. It includes an equal sign.
is an equation. It includes an equal sign.
Hope this helps you.