Note that (-6)^2 = (-6)(-6)
Multiply across. Remember that when multiplying two negative numbers, the product would be a positive answer
(-6) x (-6) = 36
36 is your answer
~<em>Rise Above the Ordinary, Senpai</em>
22.5 (shower) = X (variable used in place of the amount of water she uses to wash clothes) - 7.5 (the amount she used in the shower is 7.5 gallons less than she uses for washing clothes)
22.5 = X - 7.5 《 This is the equation.
Solve is by adding 7.5 to both sides to cancel out the negative 7.5 and you get (X = 30). Hope this helps.
<u>We are given:</u>
The time-traveller has 79 books, but he can only take 5 books
since we need to find the number of ways he can choose 5 books, we know that the order in which he takes the books does NOT matter
Hence, we will use combination
<u>Finding the number of ways:</u>
Since we will use combination, ₇₉C₅
We know that the formula for combination is (n!) / (r!(n-r)!)
₇₉C₅ = 79! / 5!(74!)
₇₉C₅ = 22,537,515
Therefore, the time traveller can choose 5 books in 22,537,515 different ways
Answer:
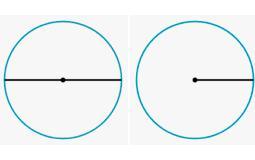
okay so you would make a line straight across the middle of the spherical shape. The line that goes all the way across is the diameter. If you were to cut that line in half that would be the radius.
Step-by-step explanation:
The first circle shown in the picture provided would be an example of diameter, and the second circle would be an example of the radius. You could just make up a value, for example say the diameter is 10, the radius would be 5.
Answer: 18 people per minute
Step-by-step explanation: 162 divide by 9 equals 18