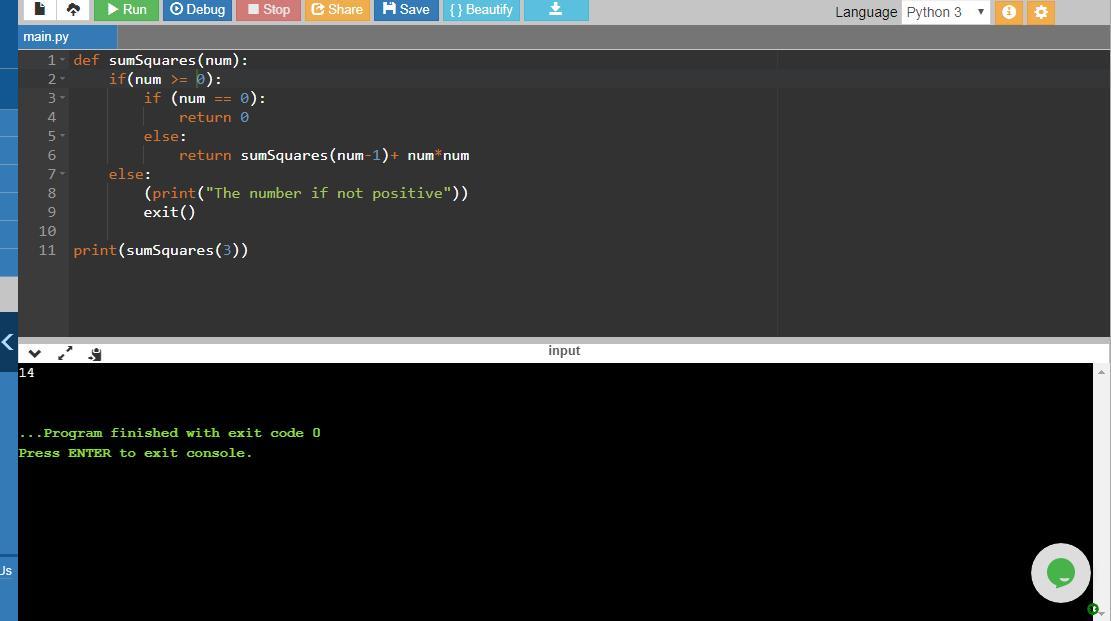
Answer:
Here is the recursive function sumSquares(num) that takes an integer num as parameter and returns the sum of squares of numbers from 1 to num.
def sumSquares(num):
if(num >= 0): # checks if the value of num is less than or equal to 0
if (num==0): #if value of num is 0
return 0 #returns 0 if value of num is 0
else: #if value of num is greater than 0
return sumSquares(num - 1)+ num * num #recursively calls the sumSquares method to return the sum of squares of numbers from 1 to num
else: # if a user enters a negative num
(print("The number if not positive")) #prints this message
exit() # exits after displaying that number if not positive message
#below print statement is used in order to check the working of the function
print(sumSquares(3)) #calls function and passes value 3 for num
Explanation:
The program works as follows:
The function sumSquares(num) that takes an integer num as parameter and returns the sum of squares of numbers from 1 to num
The first if condition checks if value of num is positive. If this condition evaluates to true then the another if statement inside this if statement is executed which checks if the value of num is 0. If this condition evaluates to true then the program returns 0. However if this condition evaluates to false then the else part executes which has the following statement:
return sumSquares(num - 1) + num * num
For example num = 3
so the above recursive statement works as follows:
sumSquares(3-1) + 3 * 3
sumSquares(2) + 9
Note that the sumSquares() method is called again and the value 2 is passed as num. As 2 is greater than 0. So again the recursive statement executes:
sumSquares(2 - 1) + 2 * 2 + 9
sumSquares(1) + 4 + 9
sumSquares(1) + 13
sumSquare() method is called again and the value 1 is passed as num. As 1 is greater than 0. So again the recursive statement executes:
sumSquares(1 - 1) + 1 * 1 + 13
sumSquares(0) + 1 + 13
sumSquares(0) + 14
sumSquare() method is called again and the value 0 is passed as num
As the value of num=0 So the if (num == 0): condition evaluates to true and the statement returns 0 executes which returns 0:
sumSquares(0) + 14
0 + 14
Hence the output is:
14
The screenshot of the program along with its output is attached.