It appears that your answer contains either a link or inappropriate words. Please correct and submit again! error
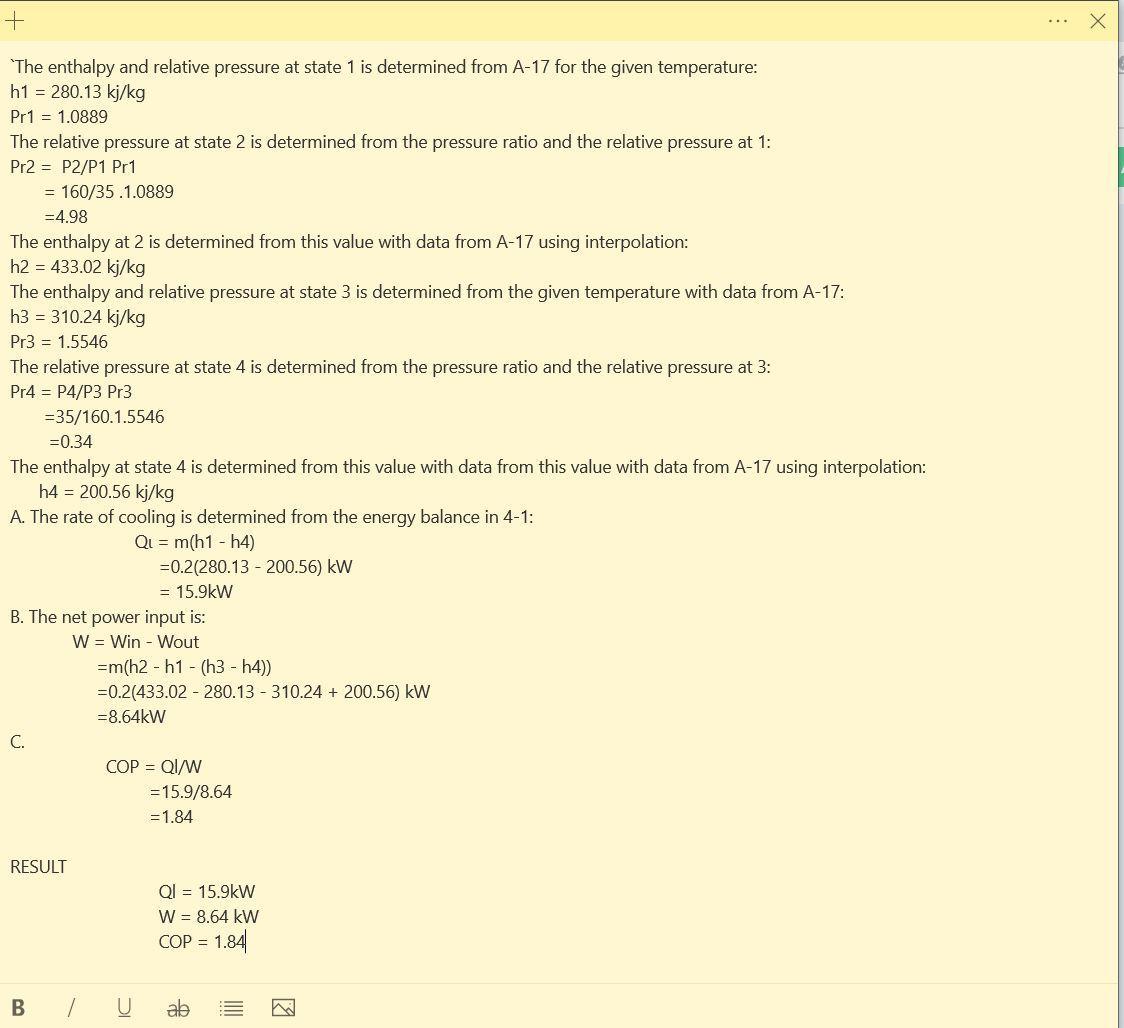
Had to screenshot the solution check attached
Answer:
Option D - the moisture content at turbine exit will decrease
Explanation:
In an ideal rankine system, the phenomenon of superheating occurs at a state where the vapor state of the fluid is heated above its saturation temperature and the phase of the fluid is changed from the vapor phase to the gaseous phase.
Now, a vapour phase has two different substances at room temperature, whereas a gas phase consists of just a single substance at a defined thermodynamic range, at standard room temperature.
At the turbine exit, since it's just a single substance in gaseous phase, it means it will have less moisture content.
Thus, the correct answer is;the moisture content at turbine exit will decrease
Answer:
Temperature on the inside ofthe box
Explanation:
The power of the light bulb is the rate of heat conduction of the bulb, 
The thickness of the wall, L = 1.2 cm = 0.012m
Length of the cube's side, x = 20cm = 0.2 m
The area of the cubical box, A = 6x²
A = 6 * 0.2² = 6 * 0.04
A = 0.24 m²
Temperature of the surrounding, 
Temperature of the inside of the box, 
Coefficient of thermal conductivity, k = 0.8 W/m-K
The formula for the rate of heat conduction is given by:

OLAP (online analytical processing) software is the software to perform various high-speed analytics of large amounts of data from a data center, data mart, or other integrated, centralized data store.
<h3>What is the use of Online Analytical Processing (OLAP)?</h3>
OLAP provides pre-calculated data for various data mining tools, business modeling tools, performance analysis tools, and reporting tools.
OLAP can help with Planning and Budgeting andFinancial Modeling. Online Analytical Processing (OLAP) is included in many Business Intelligence (BI) software applications. It is used for a range of analytical calculations and other activities.
Therefore, OLAP (online analytical processing) software is the software to perform various high-speed analytics of large amounts of data from a data center, data mart, or other integrated, centralized data store.
Learn more about Online Analytical Processing (OLAP):
brainly.com/question/13286981
#SPJ1