Answer:
Demand Paging
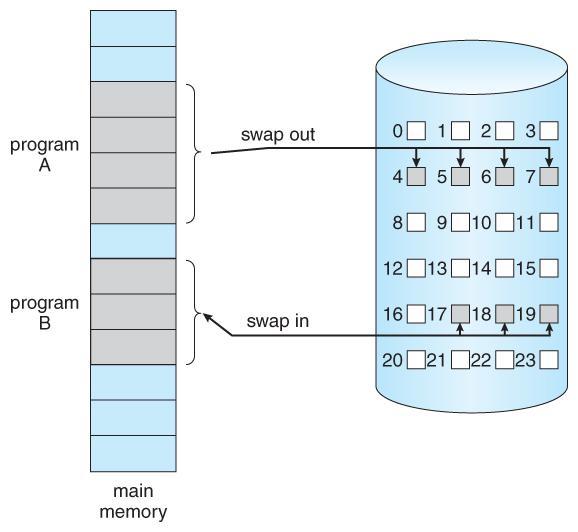
The basic idea behind demand paging is that when a process is swapped in, its pages are not swapped in all at once. Rather they are swapped in only when the process needs them. ( on demand. ) This is termed a lazy swapper, although a pager is a more accurate term.
Figure 9.4 - Transfer of a paged memory to contiguous disk space
9.2.1 Basic Concepts
The basic idea behind paging is that when a process is swapped in, the pager only loads into memory those pages that it expects the process to need ( right away. )
Pages that are not loaded into memory are marked as invalid in the page table, using the invalid bit. ( The rest of the page table entry may either be blank or contain information about where to find the swapped-out page on the hard drive. )
If the process only ever accesses pages that are loaded in memory ( memory resident pages ), then the process runs exactly as if all the pages were loaded in to memory.
Figure 9.5 - Page table when some pages are not in main memory.
On the other hand, if a page is needed that was not originally loaded up, then a page fault trap is generated, which must be handled in a series of steps:
The memory address requested is first checked, to make sure it was a valid memory request.
If the reference was invalid, the process is terminated. Otherwise, the page must be paged in.
A free frame is located, possibly from a free-frame list.
A disk operation is scheduled to bring in the necessary page from disk. ( This will usually block the process on an I/O wait, allowing some other process to use the CPU in the meantime. )
When the I/O operation is complete, the process's page table is updated with the new frame number, and the invalid bit is changed to indicate that this is now a valid page reference.
The instruction that caused the page fault must now be restarted from the beginning, ( as soon as this process gets another turn on the CPU. )
Figure 9.6 - Steps in handling a page fault
In an extreme case, NO pages are swapped in for a process until they are requested by page faults. This is known as pure demand paging.
In theory each instruction could generate multiple page faults. In practice this is very rare, due to locality of reference, covered in section 9.6.1.
The hardware necessary to support virtual memory is the same as for paging and swapping: A page table and secondary memory. ( Swap space, whose allocation is discussed in chapter 12. )
A crucial part of the process is that the instruction must be restarted from scratch once the desired page has been made available in memory. For most simple instructions this is not a major difficulty. However there are some architectures that allow a single instruction to modify a fairly large block of data, ( which may span a page boundary ), and if some of the data gets modified before the page fault occurs, this could cause problems. One solution is to access both ends of the block before executing the instruction, guaranteeing that the necessary pages get paged in before the instruction begins.
9.2.2 Performance of Demand Paging
Obviously there is some slowdown and performance hit whenever a page fault occurs and the system has to go get it from memory, but just how big a hit is it exactly?
There are many steps that occur when servicing a page fault ( see book for full details ), and some of the steps are optional or variable. But just for the sake of discussion, suppose that a normal memory access requires 200 nanoseconds, and that servicing a page fault takes 8 milliseconds. ( 8,000,000 nanoseconds, or 40,000 times a normal memory access. ) With a page fault rate of p, ( on a scale from 0 to 1 ), the effective access time is now:
( 1 - p ) * ( 200 ) + p * 8000000
= 200 + 7,999,800 * p
which clearly depends heavily on p! Even if only one access in 1000 causes a page fault, the effective access time drops from 200 nanoseconds to 8.2 microseconds, a slowdown of a factor of 40 times. In order to keep the slowdown less than 10%, the page fault rate must be less than 0.0000025, or one in 399,990 accesses.
A subtlety is that swap space is faster to access than the regular file system, because it does not have to go through the whole directory structure. For this reason some systems will transfer an entire process from the file system to swap space before starting up the process, so that future paging all occurs from the ( relatively ) faster swap space.
Some systems use demand paging directly from the file system for binary code ( which never changes and hence does not have to be stored on a page operation ), and to reserve the swap space for data segments that must be stored. This approach is used by both Solaris and BSD Unix