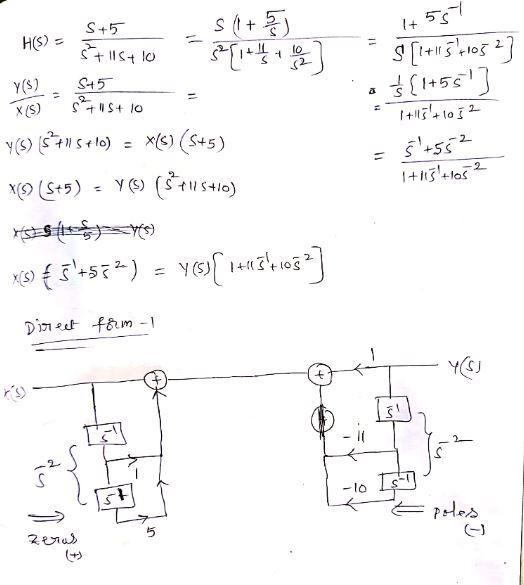
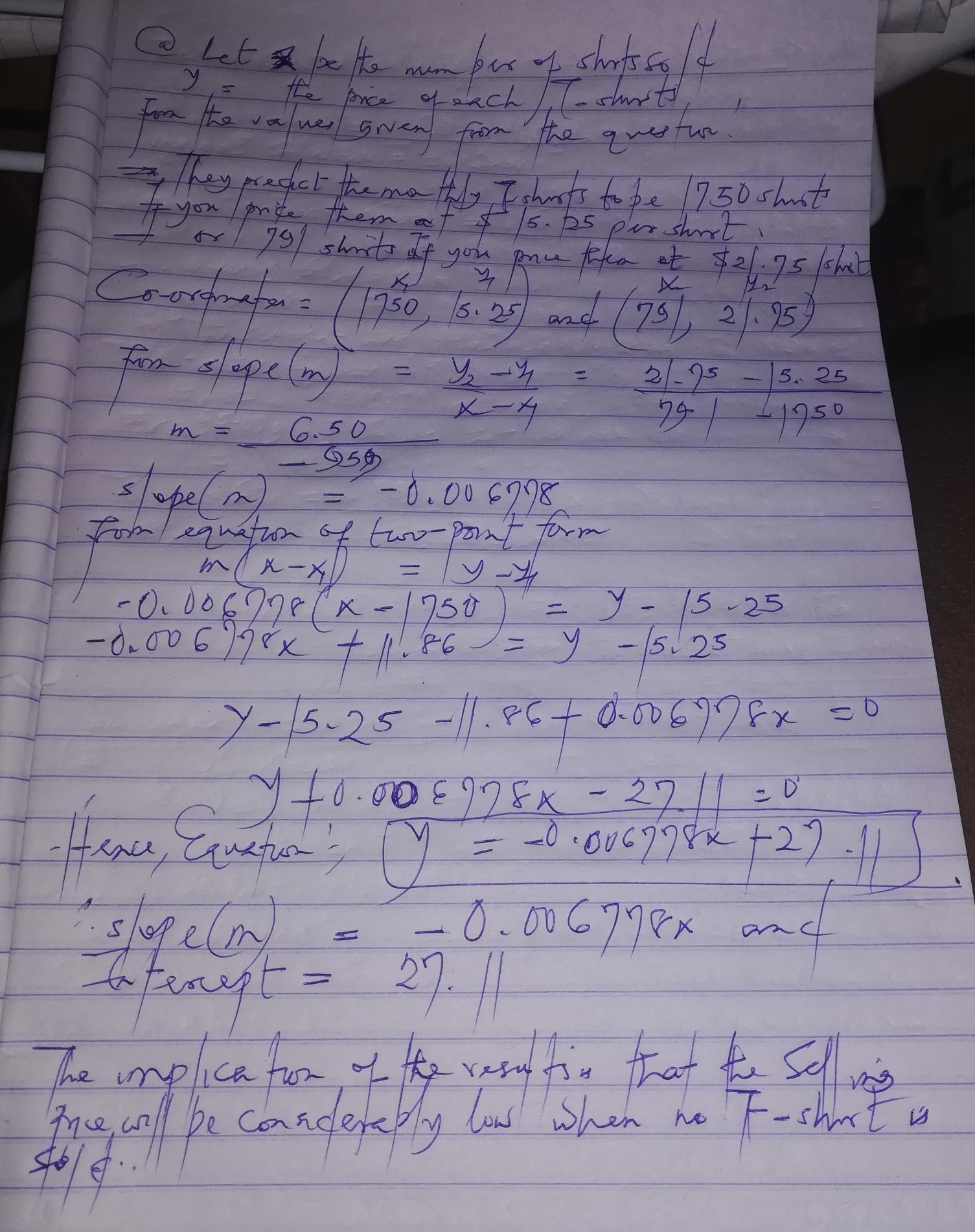Answer:
See the attached file for the answer.
Explanation:
See the attached file for the explanation
Answer:
try to 36v power and take 1a and intersect to 3
Answer:
True.
Explanation:
According the engineering flow they don not possess flow energy when they are in rest.
When they are in motion they show a translation energy.
The features if fluids may be different according the variables of pressure and temperature.
Answer:
slope of the equation = -0.006778 and the intercept = 27.11
Explanation:
The following details were also given ; They predict the monthly T shirts to be 1750 shirts, if you price them at $15.25 per shirt or 791 shirts if you price them at $21.75 per shirt.
The detailed steps and calculation is as shown in the attached file.